Multi-modal Transformer for Video Retrieval
任务
标题到视频和视频到标题检索
贡献
- 联合编码不同的视频模态(视频帧、ASR、音频)
- 对时间信息进行编码和建模
- 联合优化语言嵌入与多模态Transformer
结构
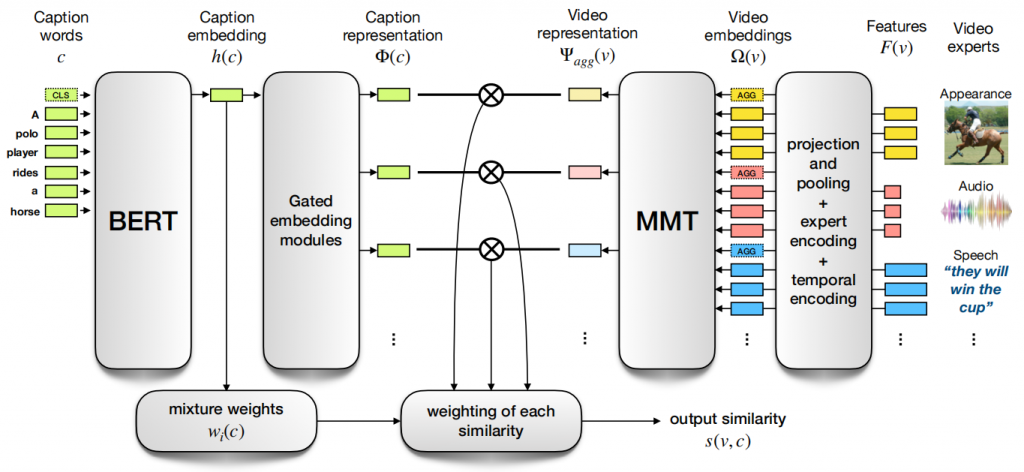
Ω(v) = F(v) + E(v) + T(v)
- F(v): 为特定任务训练的模型,用于从视频中提取特征,对于一个视频v,每个专家提取一个K个特征(为了将不同的专家特征投影到一个共同的维度空间中,每个专家配1个可学习的线性层)
- AGG: 用所有相应专家特征的最大池聚合初始化这个嵌入
- E(v): 区分不同专家的嵌入
- T(v): 时间嵌入,T1~TN,额外的Tagg和Tunk 分别编码聚合特征和未知的时间信息特征
Ψagg(v) = MMT(Ω(v))
- 只保留了每个专家的聚合嵌入
Caption
- 从 Bert 的[CLS]输出中提取
- 学习函数g与视频专家相同的门控嵌入模块
Gated embedding module

第一层描述了将输入特征Z0投影到嵌入空间Z1的过程。
第二层执行上下文门控,其中使用学习的门控权重σ(W2Z1 + b2)重新加权Z1的各个维度,其值介于0和1之间,其中W2和b2是学习参数。这种门控的动机有两个方面:(i)我们希望在Z1的各个维度之间引入非线性交互;(ii)我们希望通过自门控机制重新校准Z1的不同激活的强度。
最后,执行L2归一化,以获得最终输出Z。
w(c) 表示专家的权重
- 将h(c)通过一个线性层,然后执行一个softmax操作
![[翻译]Online Hybrid CTC/Attention Architecture for End-to-end Speech Recognition](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)