Abstract
基于Transformer的模型,例如BERT,已成为自然语言处理中最成功的深度学习模型之一。不幸的是,它有一个核心限制是全局注意力机制对序列长度具有二次方的依赖性(主要是在显存方面)。为了解决这个问题,我们提出了BIGBIRD,一种稀疏注意力机制,将这种二次依赖性降低到线性。我们展示了BIGBIRD是序列函数的通用逼近器,并且是图灵完备的,从而保留了二次全局注意力模型的这些属性。在此过程中,我们的理论分析揭示了具有O(1)全局标记(例如CLS)的一些好处,这些标记作为稀疏注意力机制的一部分关注整个序列。所提出的稀疏注意力可以在类似硬件限制下处理比之前长8倍的序列。由于具有处理更长上下文的能力,BIGBIRD在各种自然语言处理任务(例如问答和摘要)中显着提高了性能。我们还提出了基因组数据的新应用。
1 Introduction
基于Transformer的模型[91],如BERT [22,63],在各种自然语言处理(NLP)任务中取得了巨大成功,因此成为现代NLP研究的支柱。它们的多功能性和稳健性是广泛采用Transformer的主要驱动力。该模型可以轻松适应各种基于序列的任务-作为翻译[91],摘要[66],生成[15]等的seq2seq模型,或作为情感分析[83],POS标记[65],机器阅读理解[93]等的独立编码器-并且已知远远优于先前的序列模型,如LSTM [37]。 Transformer的关键创新在于引入了自我注意机制,可以并行评估输入序列的每个令牌,消除了循环神经网络(如LSTM)中的顺序依赖性。这种并行性使Transformer能够利用现代SIMD硬件加速器(如GPU / TPU)的全部功能,从而促进在前所未有的规模数据集上训练NLP模型。这种大规模数据训练的能力导致出现了像BERT [22]和T5 [75]这样的模型,它们在大型通用语料库上预训练变压器,并将知识转移到下游任务。预训练已经在低数据范围下游任务[51]以及具有足够数据[101]的任务中导致了显着的改进,因此已成为当代NLP中Transformer普及的主要力量。
自注意机制通过允许输入序列中的每个标记独立地关注序列中的每个其他标记,克服了RNN的限制(即RNN的顺序性质)。这种设计选择具有几个有趣的影响。特别是,完全自我注意力具有计算和内存要求,其与序列长度成二次关系。我们注意到,虽然语料库可能很大,但在许多应用程序中提供上下文的序列长度非常有限。使用当前常用的硬件和模型大小,这一要求转化为大致能够处理长度为512个标记的输入序列。这降低了它对需要更大上下文的任务的直接适用性,如QA[60]、文档分类等。
然而,虽然我们知道自我注意力和Transformer很有用,但我们的理论理解还很基础。自我注意力模型的哪些方面对其性能是必要的?我们对Transformer和类似模型的表达能力能说些什么?事先,甚至从设计上来看,所提出的自我注意力机制是否像RNN一样有效都不清楚。例如,自我注意力甚至不遵守序列顺序,因为它是置换等变的。这个问题已经部分得到解决,因为Yun等人[104]表明,Transformer足够表达所有具有紧凑域的连续序列到序列函数。同时,Pérez等人[72]表明,完整的Transformer是图灵完备的(即可以模拟完整的图灵机)。两个自然的问题出现了:我们能否使用更少的内积实现完全二次自我注意力方案的经验优势?这些稀疏的注意机制是否保留了原始网络的表达能力和灵活性?
在本文中,我们解决了上述两个问题,并提出了一种稀疏注意机制,可以提高需要长上下文的多种任务的性能。我们系统地开发了BIGBIRD,这是一种注意机制,其复杂度与标记数量成线性关系(第2节)。我们从图稀疏化方法中获得灵感,并理解当全注意力放松形成所提出的注意模式时,Transformer的表达能力证明出现问题的地方。这种理解帮助我们开发了BIGBIRD,它在理论上同样具有表达能力,并且在实践中也很有用。特别是,我们的BIGBIRD由三个主要部分组成:
- 一组全局标记出现在序列的所有部分。
- 所有标记都关注一组w个本地相邻标记。
- 所有标记都关注一组r个随机标记。
这使高性能的注意力机制可以扩展到更长的序列长度(8倍)。总之,我们的主要贡献是:
- BIGBIRD 满足全变压器的所有已知理论属性(第3节)。特别地,我们表明添加额外的令牌允许使用仅 O(n) 内积表达所有连续序列到序列函数。此外,我们表明在关于精度的标准假设下,BIGBIRD 是图灵完备的。
- 实证上,我们表明 BIGBIRD 建模的扩展上下文有益于各种 NLP 任务。我们在许多不同数据集上实现了问答和文档摘要的最新结果。这些结果的摘要在第4节中呈现。
- 最后,我们介绍了一种基于注意力模型的新应用,其中长上下文是有益的:提取类似 DNA 的基因组序列的上下文表示。通过更长的掩码 LM 预训练,BIGBIRD 提高了下游任务的性能,例如预测启动子区域和染色质剖面(第5节)
1.1 Related Work
有许多有趣的尝试旨在缓解Transformer的二次依赖性,可以广泛地分为两个方向。第一类工作采用长度限制并围绕其开发方法。此类别中最简单的方法只是使用滑动窗口[93],但通常大多数工作都符合以下一般范例:使用某些其他机制选择较小的相关上下文子集送入Transformer,并可选地迭代,即每次使用不同的上下文调用变压器块多次。最著名的是SpanBERT [42],ORQA [54],REALM [34],RAG [57]已经为不同的任务实现了强大的性能。然而,值得注意的是,这些方法通常需要大量的工程努力(例如通过大规模最近邻搜索进行反向传播),并且难以训练。
第二类工作质疑全注意力是否必要,并试图提出不需要全注意力的方法,从而减少内存和计算要求。著名的Dai等人[21],Sukhbaatar等人[82],Rae等人[74]提出了自回归模型,这些模型在从左到右的语言建模方面表现良好,但在需要双向上下文的任务中表现不佳。Child等人[16]提出了一种稀疏模型,将复杂度降低到O(n√n),Kitaev等人[49]通过使用LSH计算最近邻,进一步将复杂度降低到O(nlog(n))。Ye等人[103]提出了数据的二进制分区,而Qiu等人[73]通过使用块稀疏性来降低复杂度。最近,Longformer [8]引入了一种基于局部滑动窗口的掩码,其中包含少量全局掩码,以减少计算量,并将BERT扩展到更长的序列任务。最后,我们的工作与Extended Transformers Construction [4]的工作密切相关且基于其构建。这项工作旨在为Transformer中的文本编码结构。他们广泛使用全局标记的想法来实现他们的目标。我们的理论工作可以被视为为这些模型的成功提供了理论上的证明。值得注意的是,大多数上述方法都是基于启发式的,并且在经验上不如原始Transformer那样多才多艺和强大,即相同的架构在多个标准基准测试中都不能达到SoTA。 (有一个例外是Longformer,我们在所有比较中都包括它,请参见附录E.3以获取更详细的比较)。此外,这些近似不带有理论保证。
2 BIGBIRD Architecture
在本节中,我们使用广义注意机制描述BIGBIRD模型,该机制在Transformer的每个层上操作输入序列X =(x1,…,xn)∈ Rn×d。广义注意机制由有向图D描述,其顶点集为[n] = {1,…,n}。弧(有向边)集表示注意机制将考虑的内积集。设N(i)表示D中节点i的出邻居集,则广义注意机制的第i个输出向量定义为:

其中Qh,Kh:Rd → Rm分别是查询和键函数,Vh:Rd → Rd是值函数,σ是评分函数(例如softmax或hardmax),H表示头数。还请注意,XN(i)对应于仅堆叠{xj:j∈N(i)}而不是所有输入形成的矩阵。如果D是完整的有向图,则我们恢复了Vaswani等人的完整二次注意机制[91]。为了简化我们的阐述,我们将在图D的邻接矩阵A上操作,即使底层图可能是稀疏的。具体而言,A∈[0,1]n×n,其中A(i,j)=1表示查询i关注键j,否则为零。例如,当A是全1矩阵(如BERT中),它会导致二次复杂度,因为所有标记都会关注其他标记。将自我关注视为完全连接的图,可以利用现有的图论来帮助减少其复杂度。现在,将自我关注的二次复杂度降低的问题可以看作是一个图稀疏化问题。众所周知,随机图是扩展器,并且可以在许多不同的上下文中近似完全图,包括它们的谱特性[80,38]。我们认为,用于注意机制的稀疏随机图应具有两个期望:节点之间的平均路径长度较小和局部性的概念,我们将在下面讨论每个期望。
让我们考虑最简单的随机图构造,即Erdős-Rényi模型,其中每条边都以固定概率独立选择。在这样一个仅有约Θ(n)条边的随机图中,任意两个节点之间的最短路径是节点数量的对数[17, 43]。因此,这样一个随机图在谱上近似于完全图,其邻接矩阵的第二个特征值与第一个特征值相差很远[9, 10, 6]。这个特性导致了随机游走在图中的快速混合时间,这意味着信息可以在任意一对节点之间快速流动。因此,我们提出了一种稀疏注意力,其中每个查询关注r个随机选择的键,即A(i,·) = 1,其中r是随机选择的键的数量(见图1a)。

第二个启发BIGBIRD创建的观点是,在NLP和计算生物学中的大多数上下文中,数据显示出很强的引用局部性。在这种现象中,可以从相邻的标记中推导出有关标记的大量信息。最相关的是,Clark等人[19]研究了NLP任务中的自我关注模型,并得出结论,相邻的内积非常重要。语言结构中标记的接近性概念也构成了各种语言理论的基础,例如转换生成语法。在图论术语中,聚类系数是连接性的局部性度量,当图包含许多团或近似完全互连的子图时,聚类系数很高。简单的Erd ̋os-Rényi随机图没有高聚类系数[84],但一类随机图,称为小世界图,表现出高聚类系数[94]。Watts和Strogatz [94]介绍的一个特定模型对我们非常相关,因为它在平均最短路径和局部性概念之间实现了良好的平衡。他们的模型的生成过程如下:构造一个正则环形格,每个节点都连接到w个邻居,每侧w/2个。
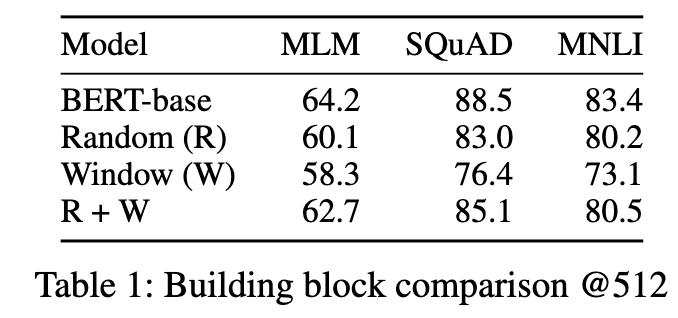
换句话说,我们从节点上开始使用滑动窗口。然后,将所有连接的随机子集(k%)替换为随机连接。保留其他(100-k%)的本地连接。但是,在现代硬件上删除这些随机边可能效率低下,因此我们保留它,这不会影响其属性。总之,在BIGBIRD中,为了捕捉上下文中的这些局部结构,我们定义了一个滑动窗口注意力,因此在宽度为w的自我关注期间,位置i的查询从i-w/2到i+w/2的键进行关注。在我们的符号表示中,A(i,i-w/2:i+w/2)= 1(见图1b)。作为初始的合理性检查,我们进行了基本实验,以测试这些直觉是否足以获得接近BERT模型的性能,同时保持关注线性化的令牌数量。我们发现,随机块和本地窗口不足以捕捉所有必要的上下文,以与BERT的性能竞争。
BIGBIRD的最后一部分受到我们的理论分析(第3节)的启发,这对于实证表现至关重要。更具体地说,我们的理论利用了“全局标记”的重要性(这些标记关注序列中的所有标记,并且所有标记都关注它们(见图1c)。这些全局标记可以通过两种方式定义。
- BIGBIRD-ITC:在Transformer内部构造(ITC)中,我们使一些现有的令牌“全局化”,这些令牌覆盖整个序列。具体而言,我们选择一个索引子集G(其中g:= | G |),使得对于所有i∈G,A(i,:) = 1且A(:,i)= 1。
- BIGBIRD-ETC:在Transformer扩展构造(ETC)中,我们包括额外的“全局”令牌,例如CLS。具体而言,我们添加g个全局令牌,这些令牌与所有现有令牌一起参与。在我们的符号表示中,这相当于通过向矩阵A添加g行来创建一个新矩阵B∈[0,1](N + g)×(N + g),使得B(i,:) = 1,并且对于所有i∈{1,2,… g},B(:,i)= 1,并且B(g + i,g + j)= A(i,j)∀i,j∈{1,…,N}。这增加了额外的位置来存储上下文,并且正如我们将在实验中看到的那样,可以提高性能。
BIGBIRD的最终注意机制(图1d)具有这三个属性:查询关注r个随机键,每个查询关注其位置左侧和右侧w/2个令牌,并且它们包含g个全局令牌(全局令牌可以来自现有令牌或额外添加的令牌)。我们在App.D中提供实现细节。
3 Theoretical Results about Sparse Attention Mechanism | 关于稀疏注意机制的理论结果
在本节中,我们将展示稀疏注意机制在两个方面上与全注意机制一样强大和表达力。首先,我们展示当稀疏注意机制被用于独立编码器(如BERT)时,它们是Yun等人[104]风格的序列到序列函数的通用逼近器。我们注意到这个属性在当代工作Yun等人[105]中也被理论上探讨过。其次,与[105]不同,我们进一步展示稀疏编码器-解码器变压器是图灵完备的(假设在[72]中定义的相同条件)。补充上述积极结果,我们还展示转向稀疏注意机制会产生代价,即没有免费的午餐。在第3.4节中,我们通过展示一个自然任务的下限来展示需要多项式更多层数的任何足够稀疏的机制。
3.1 Notation
完整的Transformer encoder堆栈仅是单层编码器(具有独立参数)的重复应用。我们用广义编码器(第2节定义)定义了这样的Transformer编码器堆栈类,记为TH,m,qD,其中包括H个大小为m的头和q是输出网络的隐藏层大小,注意层由有向图D定义。我们提出的注意机制与Vaswani等人[91],Yun等人[104]的注意机制的关键区别在于,我们在每个序列的开头添加了一个特殊标记,并为其分配了一个特殊向量。我们将其称为x0。因此,我们的图D将具有顶点集{0}∪[n] = {0,1,2,…,n}。我们假设这个额外的节点及其相应的向量将在transformer的最终输出层中被删除。为避免繁琐的符号表示,我们仍将transformer视为将序列X∈Rn×d映射到Rn×d的映射。我们还允许transformer在输入层中附加位置嵌入E∈Rd×n到矩阵X中。最后,我们需要定义函数类和距离度量,以证明通用逼近性质。让FCD表示连续函数集f:[0, 1]n×d→Rn×d,这些函数与由lp范数定义的拓扑连续。回想一下,对于任何p≥1,lp距离=dp(f1,f2)=(∫‖f1(X)−f2(X)‖ppdX)1/p。
3.2 Universal Approximators | 通用逼近器
略
3.3 Turing Completeness |图灵完备性
transformer非常通用。在 Vaswani 等人的原始论文 [91] 中,它们被用于编码器和解码器。虽然前面的部分概述了编码器的强大之处,但另一个自然的问题是问一个解码器和编码器的附加能力是什么?Pérez 等人 [72] 表明,基于二次注意机制的完整transformer是图灵完备的。这个结果做出了一个不现实的假设,即模型在任意精度模型上工作。当然,这是必要的,否则,transformer是有限状态机,不能是图灵完备的。
自然而然地问,完整的注意机制是否是必要的。或者可以使用稀疏的注意机制来模拟任何图灵机吗?我们表明,这确实是可能的:我们可以使用稀疏编码器和稀疏解码器来模拟任何图灵机。 为了在transformer架构中使用稀疏注意机制,我们需要定义一个适当的修改,其中每个令牌只对先前的令牌做出反应。与 BERT 的情况不同,在完整的transformer中,解码器侧的稀疏注意机制是逐个令牌使用的。其次,Pérez 等人的工作 [72] 使用每个令牌作为磁带历史的表示,并使用完整的注意力来移动和检索正确的磁带符号。Pérez 等人的大部分构造 [72] 都适用于稀疏注意力,除了它们指向历史的 addressing scheme(引理 B.4 在 [72] 中)。我们展示了如何使用稀疏注意机制来模拟这个,并将细节推迟到 App.B。
3.4 Limitations
我们展示了稀疏注意机制不能普遍替代密集注意机制,即没有免费的午餐。我们展示了一个自然任务,可以通过O(1)层的完全注意机制来解决。然而,在标准复杂性理论假设下,对于任何具有 ̃O(n)边缘(不仅仅是BIGBIRD)的稀疏注意层,该问题需要 ̃Ω(n)层。 (这里 ̃O隐藏了多项式对数因子)。考虑在给定长度为n的序列中找到每个向量的相应最远向量的简单问题。形式上来说。
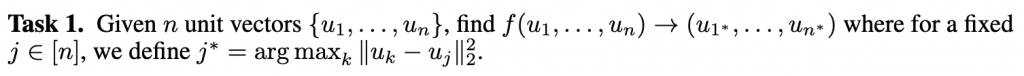
寻找距离最远的向量归结为在单位向量情况下最小化内积搜索。对于具有适当查询和键的全注意机制,这个任务非常容易,因为我们可以评估所有成对的内积。
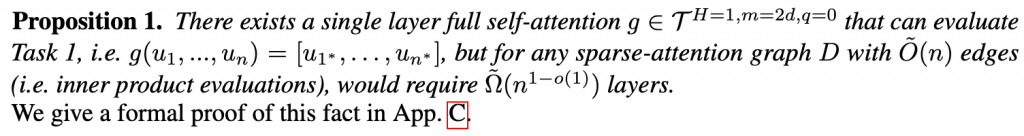
4 Experiments: Natural Language Processing
在这个部分,我们的目标是展示对于NLP任务建模更长的输入序列的好处,为此我们选择了三个代表性任务。我们从基本的掩码语言建模(MLM;Devlin等人22)开始,以检查是否可以通过利用更长的连续序列来学习更好的上下文表示。接下来,我们考虑支持证据的问答,对于这种任务,处理更长的序列的能力将允许我们使用粗糙的系统(如TF-IDF/BM25)检索更多的证据。最后,我们处理长文档分类,其中区分信息可能不在前512个标记中。下面我们总结了使用序列长度40961的BIGBIRD的结果,而我们将所有其他设置细节,包括计算资源、批量大小、步长等列在App.E。

Pretraining and MLM 我们遵循[22,63]来创建BIGBIRD的基础和大版本,并使用MLM目标进行预训练。该任务涉及预测已屏蔽的随机子集的标记。我们使用四个标准数据集进行预训练(列在App.E.1,Tab.9中),从公共RoBERTa检查点2开始热启动。我们比较预测按字符的位数来衡量的屏蔽标记的性能,如[8]所述。如App.E.1,Tab.10所示,BIGBIRD和Longformer的表现均优于有限长度的RoBERTa,其中BIGBIRD-ETC表现最佳。我们注意到,我们的模型在16GB内存/芯片和32-64的批量大小下进行了合理的训练。我们的内存效率归功于第2节中描述的高效阻塞和稀疏注意机制的稀疏结构。
问题回答(QA)我们考虑了以下四个具有挑战性的数据集:
- 自然问题[52]:对于给定的问题,从给定的证据中找到一个短的答案(SA),并突出显示包含有关正确答案(LA)信息的段落。
- HotpotQA-distractor [100]:与自然问题类似,需要从给定的证据中找到答案(Ans)以及支持事实(Sup),以进行多跳推理。
- TriviaQA-wiki [41]:我们需要使用提供的维基百科证据为给定的问题提供答案,但是答案可能不在给定的证据中。在一个较小的已验证问题子集上,给定的证据保证包含答案。然而,在这种情况下,我们也将答案建模为跨度选择问题。
- WikiHop [ 95]: 通过聚合给定证据中分散的信息,从多项选择题中选择正确选项。
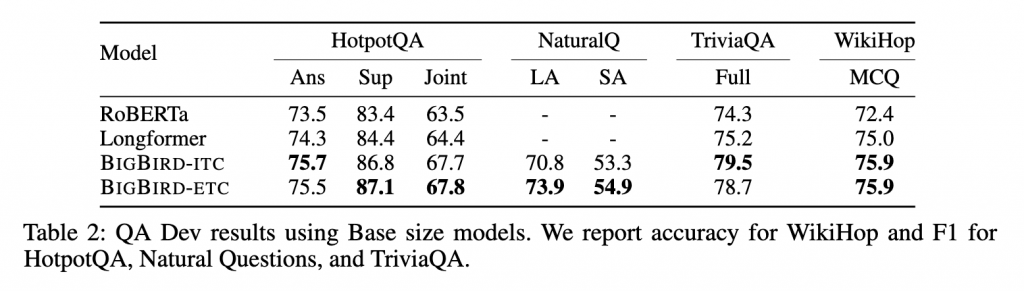
由于这些任务非常具有竞争性,因此设计了多个高度工程化的系统,每个数据集都符合相应的输出格式。为了公平比较,我们不得不对BIGBIRD进行一些额外的正则化训练,具体细节在附录E.2中提供,同时提供了精确的架构描述。我们使用基本大小模型进行实验,并选择每个数据集开发集中的最佳配置(如Tab.2所述)。我们可以看到,具有扩展全局标记的BIGBIRD-ETC始终优于所有其他模型。因此,我们选择此配置来训练一个大型模型,以用于评估隐藏测试集。在Tab.3中,我们将BIGBIRD-ETC模型与排行榜中排名前三的条目(不包括BIGBIRD)进行比较。可以清楚地看到使用更长的上下文的重要性,因为Longformer和BIGBIRD都优于具有较小上下文的模型。此外,值得注意的是,BIGBIRD提交是单个模型,而自然问题的其他前三名条目是集合,这可能解释了在精确答案短语选择方面略低的准确性。
Classification 我们在不同长度和内容的数据集上进行实验,特别是各种文档分类和GLUE任务。在BERT之后,我们在第一个[CLS]标记之上使用了一个层和交叉熵损失。我们发现,在文档更长且训练示例更少的情况下,使用BIGBIRD的收益更为显著。例如,使用基础大小模型,BIGBIRD将Arxiv数据集的最新技术水平提高了约5个百分点。在专利数据集上,与使用简单的BERT / RoBERTa相比,有所改进,但考虑到训练数据的大量大小,与SoTA(不基于BERT)相比的改进并不显著。请注意,这种性能提升在更小的IMDb数据集中并没有看到。除了实验设置细节外,我们还在App. E.4中提供了详细的结果,显示了竞争性能。
4.1 Encoder-Decoder Tasks
对于编码器-解码器设置,人们可以很容易地看到,由于完全的自我关注,两者都遭受二次复杂度的影响。我们只在编码器端重点介绍BIGBIRD的稀疏注意力机制。这是因为,在实际的生成应用中,输出序列的长度通常比输入序列小。例如,对于文本摘要,我们在现实场景中看到(参见应用程序。E.5选项卡。18),中位数输出序列长度为200,而输入序列的中位数长度>3000。对于这样的应用,编码器使用稀疏注意力机制,解码器使用全自注意力机制更有效。
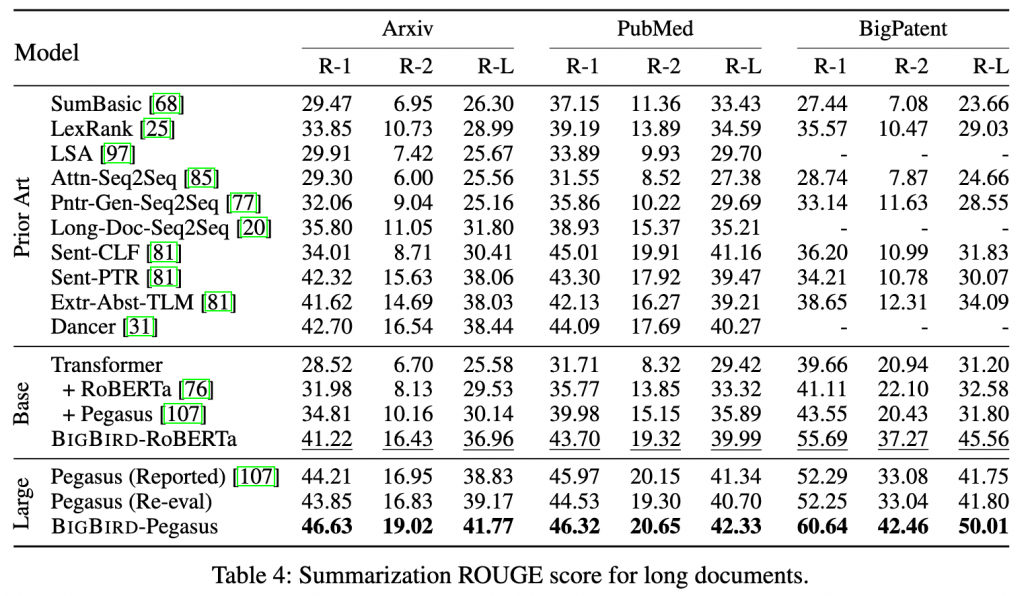
Summarization 文档摘要是创建文本文档的简短而准确的摘要的任务。我们使用了三个长文档数据集来测试我们的模型,详细信息在表18中提到。在本文中,我们专注于长文档的抽象摘要,其中使用更长的上下文编码器应该可以提高性能。原因有两个:首先,显着的内容可以均匀地分布在长文档中,而不仅仅是在前512个标记中,这是在BigPatents数据集[78]中设计的。其次,较长的文档展现出更丰富的话语结构,摘要更加抽象,因此观察更多的上下文有助于提高性能。正如最近指出的[76,107],预训练有助于生成任务,我们从基础大小模型的通用MLM预训练开始,以及利用来自Pegasus [107]的最先进的摘要特定预训练在大型模型上。在这些长文档数据集上训练BIGBIRD稀疏编码器以及完整的解码器的结果在表4中呈现。我们可以清楚地看到,对更长的上下文进行建模会带来显着的改进。除了超参数之外,我们还在App.E.5中展示了更短但更广泛的数据集的结果,这表明使用稀疏注意力也不会影响性能。
6 Conclusion
我们提出了BIGBIRD:一种在标记数量方面呈线性的稀疏注意机制。BIGBIRD满足许多理论结果:它是序列到序列函数的通用逼近器,也是图灵完备的。从理论上讲,我们利用额外的全局标记的能力来保留模型的表达能力。我们通过展示转向稀疏注意机制确实会产生成本来补充这些结果。在实证方面,BIGBIRD在诸如问答和长文档分类等许多NLP任务中表现出最先进的性能。我们进一步介绍了基于注意力的DNA上下文语言模型,并对其进行微调,以用于下游任务,例如预测启动子区域和预测非编码变异的影响。
![[翻译]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)
