A Versatile Backbone for Dense Prediction without Convolutions
Abstract
尽管使用CNN作为骨干网络的结构在视觉领域取得巨大成功,本文介绍了一个简单的无CNN的骨干网络用于密集预测任务(指目标检测和分割)。不像ViT这种最近提出的特别为图像分类设计的Transformer模型,我们提出Pyramid Vision Transformer(PVT)克服了将Transformer移植到各种密集预测任务上的困难。PVT有以下几个价值:
- 不同于ViT使用低分辨率输出和高计算量和显存占用,PVT不仅可以在对密集预测很重要的图像密集区域获得高分辨率输出,还使用了逐渐缩小的金字塔结构来减少大特征图的计算量
- PVT继承了CNN和Transfomer的优势,直接替换CNN骨干网络即可在多种任务中通用
- 我们对PVT进行了大量实验证明其能提升大量下游任务的表现,如目标检测、语义和实例分割。
我们希望PVT可以成为像素级预测上的可选和有用的骨干网络,开源地址
Introduction
本文探究了在密集预测任务中不使用CNN的模型,如目标检测、语义和实例分割、甚至分类。
受到Transformer在NLP领域成功的影响,许多人尝试探究Transformer在视觉领域的应用。一些工作将视觉任务建模为具有可学习queries的字典查找问题,使用Transformer解码器作为任务头接在CNN骨干网络上;一些工作是将注意力机制融入CNN网络中。据本文所知,直接使用Transformer完成密集预测任务的工作几乎没有。最近ViT将Transformer用于图像分类,但是又重又不通用。本文提出的PVT克服了使用Transformer的困难:
- 使用4×4图像块作为细粒度输入得到高分辨率特征,可以用于密集预测任务
- 引入渐进收缩金字塔结构,在深度增加时减小Transformer的序列长度,大大减少了计算量
- 使用空间减少注意力(SRA)层进一步减少学习高分辨率特征的成本
本文主要贡献有:
- 提出不使用卷积的适合多种像素级预测任务的骨干模型PVT
- 克服了很多困难设计了金字塔结构和SRA,在使用Transformer的过程中降低了资源消耗
- 在很多实验上验证PVT
Pyramid Vision Transformer
Overall Architecture
PVT的总览如图所示,和CNN骨干网络相似,有四个阶段生成不同尺度的特征图。所有阶段都是相似的结构,由patch embedding层和Transformer Encoder层组成。
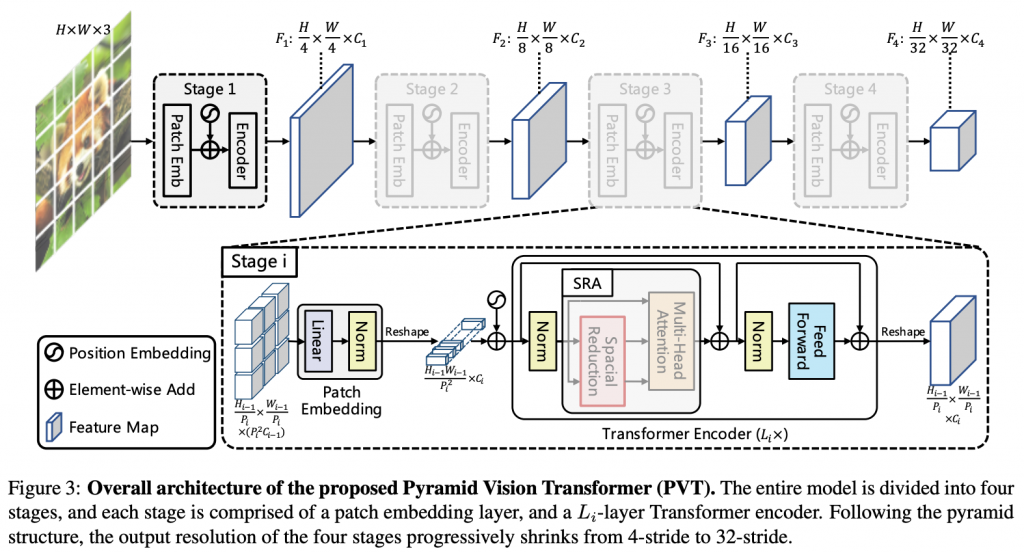
- 输入HxWx3的图像,首先将其分成HW/42个图像块,每个图像块的尺寸为4x4x3。
- 将每个图像块线性变换至长度为C1的embedded块,总尺寸为HW/42xC1 。
- 将embeded块和position embedding组合,送入Transformer编码器的L1层,得到F1 ,其尺寸为HW/42xC1。
- 继续送入下一层,得到F2、F3、F4,步长相对于输入图像分别为8、16、32。
- 得到金字塔结构的「F1,F2,F3,F4」特征后,就可以很方便的用到各种下游任务中了。

Feature Pyramid for Transformer
不像CNN使用步长来得到多尺度特征图,PVT使用逐渐收缩策略(progressive shrinking strategy)控制特征尺度。我们使用Pi表示第i阶段后的patch尺寸,将输入特征Fi-1∈R「Hi-1 x Wi-1 x Ci-1」均匀的切分为Hi-1Wi-1 / Pi2个patch,然后将每个patch展开并投影至Ci维的embedding。在线性投影后,可将embedding视为Hi-1/Pi x Wi-1/Pi x Ci的特征块,其H和W比输入特征小了Pi倍。这样就可以灵活的调整每层的特征尺度,使Transformer产生特征金字塔。
Transformer Encoder
Transformer的第i阶段有Li层编码层,每层由注意力层和前向层组成。由于PVT需要处理高分辨率特征图,我们提出SRA(spatial-reduction attention)代替多头注意力(MHA)。SRA也接受Q、K、V作为输入,不同在于SRA将在注意力操作前降低K和V的空间尺度,以此大量降低计算量和参数量(降低Ri2,Ri为降低倍率),如图所示。
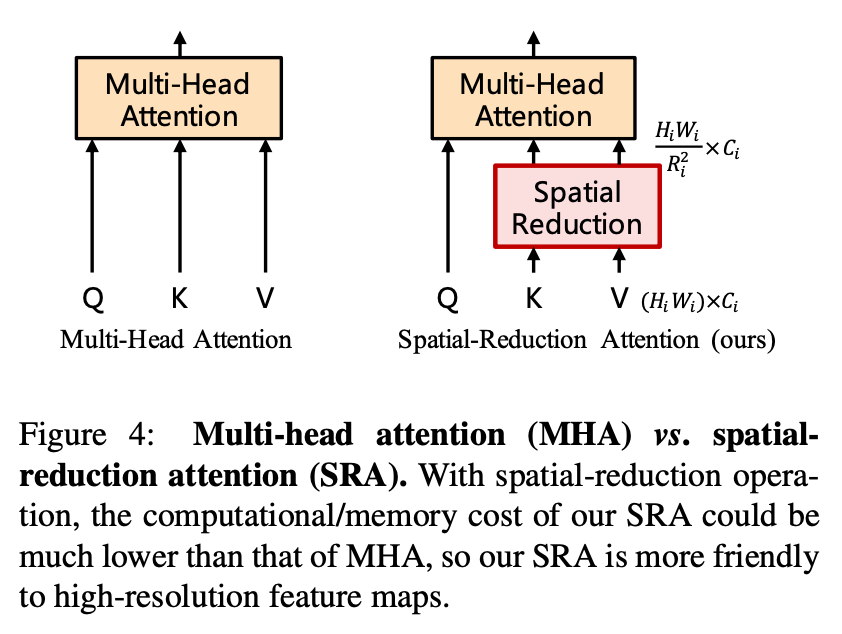
# SR
sel.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
# Forward of SR
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
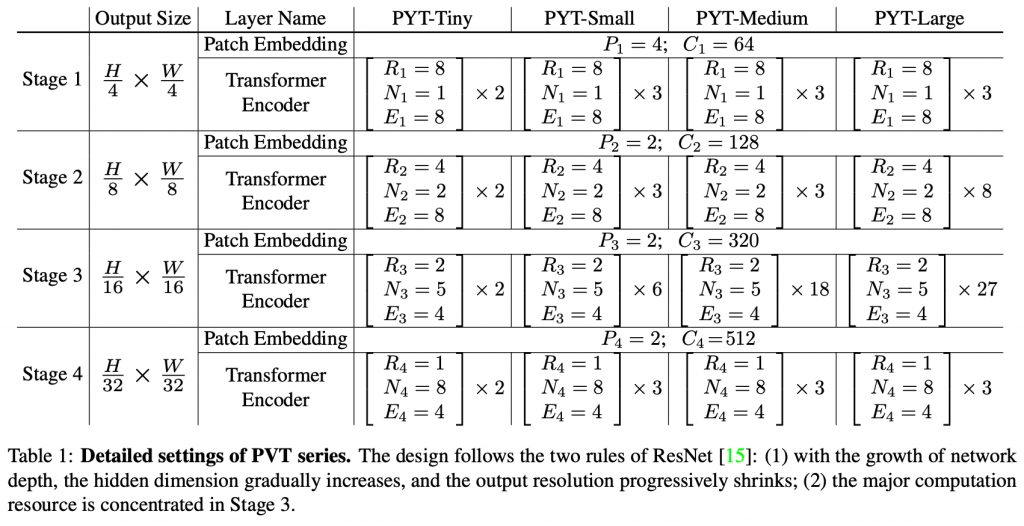
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)Model Details

Discussion
ViT的问题有:
- 它全程只能输出16-stride或者32-stride的feature map
- 一旦输入图像的分辨率稍微大点,占用显存就会很高甚至显存溢出。
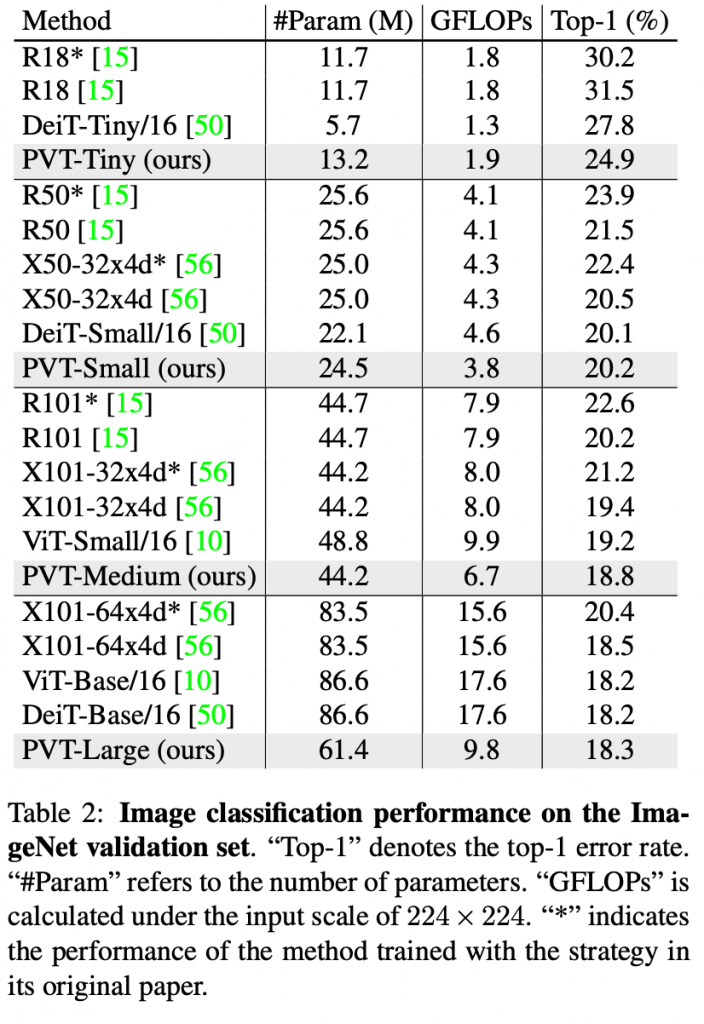
Applied to Downstream Tasks
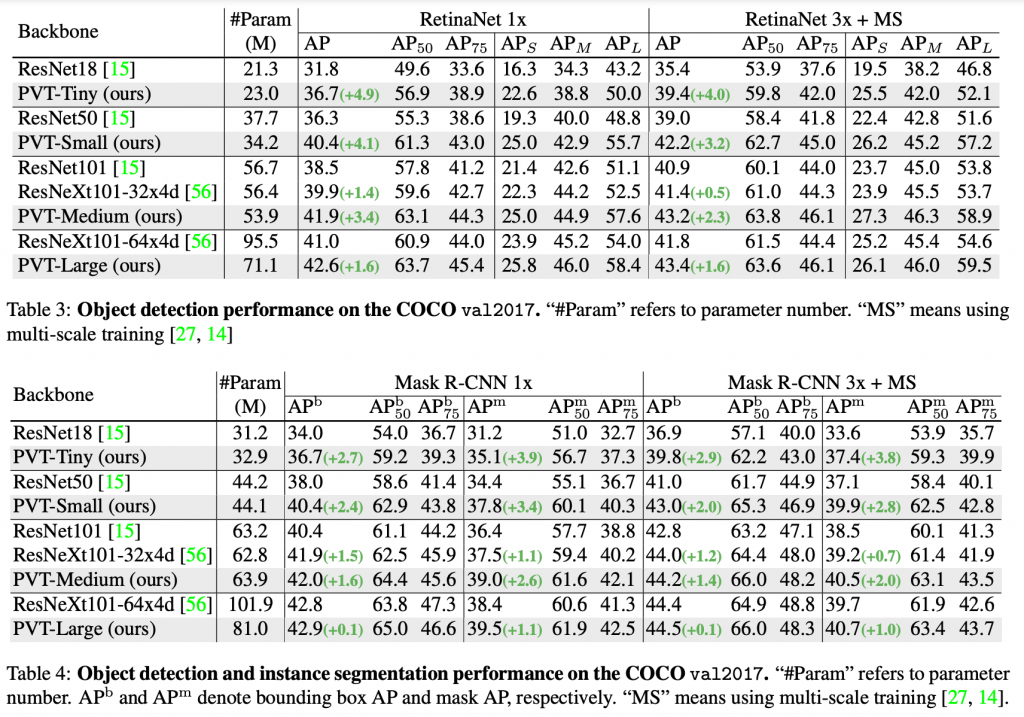
Conclusion
- Transformer在视觉上还比较稚嫩,本文没有和ResNest等更好的网络比较
- 未进一步探究 Position Embedding
![[转载]ZLPR: A NOVEL LOSS FOR MULTI-LABEL CLASSIFICATION](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)