《A Self-Supervised Descriptor for Image Copy Detection》from Meta AI
Abstract
图像复制检测是内容审核的一项重要任务。我们引入了SSCD,这是一个建立在最近的自监督对比训练目标上的模型。我们修改模型架构和训练目标应用到这项任务中,包括实体匹配文本的池化操作、使对比学习可用于组合图像的增强上。
我们使用了熵正则化项,促进描述向量之间的consistent separation,并证明了它显著提高了复制检测正确率。我们的方法能输出紧凑的描述符向量,适用于现实世界的网络级规模应用。来自背景图像分布的统计信息可以合并到描述符中。
在最近的DISC2021基准测试中,SSCD比复制检测基线模型和专为图像分类设计的自监督模型在所有赛段中都出色。例如,SSCD的绝对性能优于SimCLR描述符48%。
开源地址:https://github.com/facebookresearch/sscd-copy-detection
1.Introduction
所有在线图片分享平台都使用内容审核来限制或拒绝被认为有害的图像传播,如恐怖主义宣传、虚假信息、骚扰、色情等。对于色情图片等明确的数据,内容审核可以自动执行,但对于表情包或虚假信息等复合数据,这要困难得多,因此需要人工审核。对于这些病毒图像来说,同一图像的副本可能会被上传数千次,每个副本的手动审核是乏味和不必要的。相反,每个需要手动审核决定的图像都可以记录在数据库中,以便以后可以重新识别并自动处理。
本文关注的是重新识别这一基本任务。这不是微不足道的,因为复制的图像经常因技术原因而被更改(例如,用户分享手机屏幕截图附带了额外内容),或者用户可能会进行对抗性编辑以逃避审核。
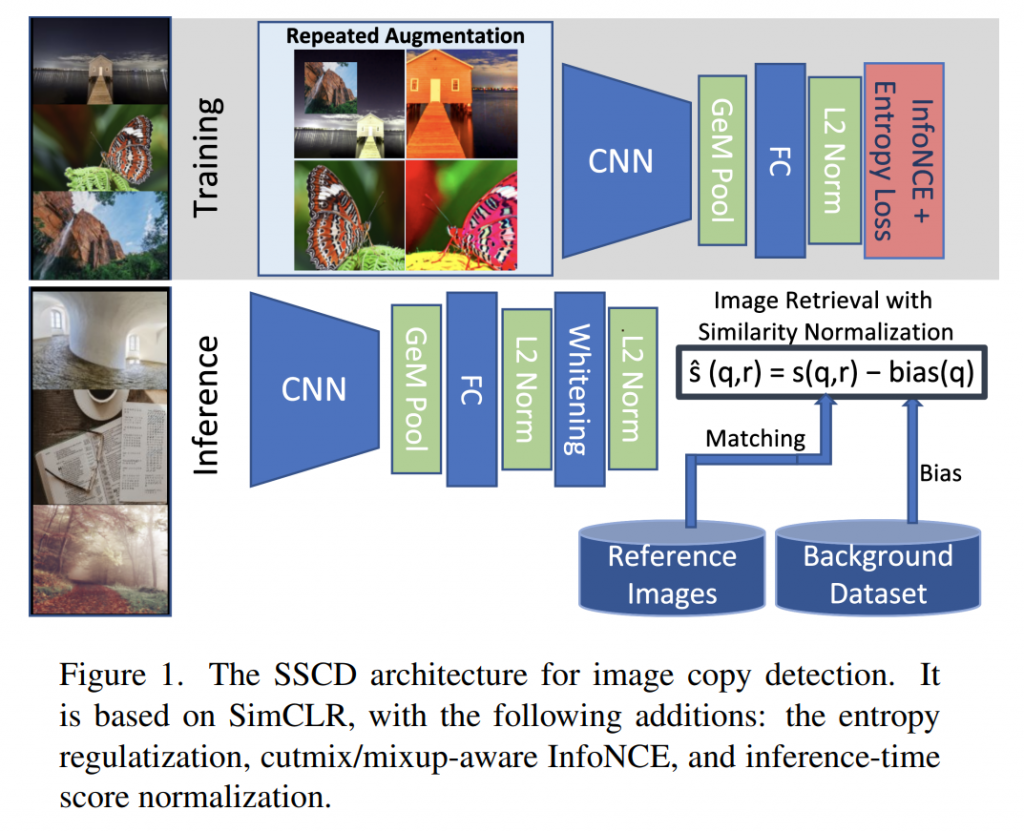
图像重新识别是一个图像匹配问题,附加两个挑战。一是副本检测系统部署后需应对巨大规模的数据,使得唯一可行的方法是将图像表示为能被近似最近邻搜索方法快速查询的短描述符向量。副本检测系统通常执行两个阶段,在检索阶段生成候选匹配短链,在验证阶段对候选短链进行局部描述符匹配。本文关注的是第一阶段,图1为SSCD的整体架构。第二个挑战是需要做出确定的匹配或不匹配决策,且图像正例对很少。我们希望使用阈值来限制验证候选者,这比典型的图像检索设置更难约束,在图像检索中,只有结果的顺序才重要。
SSCD使用微分熵正则化来促进均匀的嵌入分布,这有三个效果:(1)它使来自不同嵌入区域的距离更具可比性;(2)它避免了[29]中描述的嵌入崩溃,充分利用了嵌入空间;(3)它还改进了排名指标,不需要查询之间的一致阈值。
分数规范化对排序系统很重要。先进的分数规范化方法依赖于将查询图像与一组背景图像匹配。在这项工作中,我们展示了如何将这种规范化合并到图像描述符本身中。我们预计这项工作将为图像复制检测设置一个强大的单模型基线。
2.Related work
内容追踪方法:用户产生图像分享平台的内容追踪方法旨在识别重新进入平台的图像,有三种主流方法:基于图像元数据、基于水印、基于内容,本文属于最后一种。用于内容追踪的经典图像数据集,如Casia,专注于拼接、移除和复制移动转换等图像更改,这些更改仅改变图像表面的一小部分,因此重新识别可以通过简单的特征点的技术可靠地实现。挑战在于检测被篡改的表面,这通常是通过受图像分割启发的深度模型来处理的。一个相关的研究线是图像系统发育:目标是识别应用于初始和最终状态之间的一系列图像编辑方法。本文专注于识别本身,如强变形和需要被区分的几乎重复,如图2。

语义和感知图像比较:多种近似图像匹配的定义组成了像素级复制和实例匹配之间的连续体。本文所用定义为:图像被认为是副本,当且仅当它们来自相同的2D图像源。更宽松的定义例如,允许匹配视频中相邻帧。有大量关于解决实例匹配的文献,例如通过视角/相机变化识别相同的3D对象。本文建立在这些文献的基础上,因为它们解决了复杂的图像匹配,且具我们所知,近期严格复制检测的工作和基线是很稀少的。
实例匹配:经典实例匹配依赖于3D匹配工具,如兴趣点。基于CNN的方法使用来自图像分类的主干,预训练的或是端到端的,有两种方法(1)将最后一层CNN激活层转化为向量的最大池化或更通用的GeM池化,一种Lp规范化方式,p与图像分辨率有关;(2)向量的仔细规范化,除了简单的L2正则化,“whitening” is often used to compare descriptors,另一种规范化技术对比了图像背景分布的距离。本文将这些池化和规范化技术应用于复制检测。
对比自我监督学习:最近的一系列自我监督学习研究使用对比目标来学习将转换后的图像组合在一起的图像表示。这些方法要么区分图像特征,要么区分这些图像特征的集群分配。这些方法有的依赖于存储库,有的依赖于大批次训练。SimCLR使用变形图像匹配作为代理任务,学习通用图形表示,可以很好的迁移到其他任务如图像分类中去。对比 InfoNCE 损失函数,用于映射向量空间附近的相同来源的图像。
微分熵正则化:增加媒体描述符的熵迫使它们散布在表示空间中。 Sablayrolles 观察到可以使用 KozachenkoLeononenko 微分熵估计器在局部估计熵,可以将其直接合并到损失中以最大化描述符熵。 El-Nouby 的工作最接近我们的方法。 它在微调时将熵项添加到对比损失中,以提高类别和实例检索的准确性。 我们的方法类似,应用于自监督目标和图像复制检测。
3.Motivation
这个部分从SimCLR方法开始阐述,然后组合《Spreading vectors for similarity search》中的熵损失来执行一个实验,观察它对分类任务和复制检测任务的影响。
3.1.Preliminaries:SimCLR
在小批量尺度上可以最好的解释SimCLR训练。对于batch为N的图像,对每个图象创建两个增强副本,
产生2N个变换图像。正例匹配图像对为P={(i,i+N),(i+N,i)}i=1…N ,对于图像i记其正例为Pi={j|{i,j}∈P} 。每个图像使用CNN骨干网络进行映射,在最后一个平均池化激活层输出,然后使用两层MLP映射至L2正则化的描述空间zi∈Rd 。描述子使用cos相似度进行比较:sim(zi,zj)=ziTzj 。InfoNCE对比损失使相似副本之间的相似性相对于不同副本之间的相似性差距最大化。在推理时,SimCLR丢弃训练时的MLP曾,直接使用CNN池化后的特征。
l_{i,j} = -log\frac{exp(s_{i,j})}{\sum_{k\neq i}exp(s_{i,k})}L_{InfoNCE}=\frac{1}{|P|}\sum _{i,j∈P} l_{i,j}InfoNCE损失:SimCLR的 InfoNCE损失是带温度的softmax交叉熵,将描述符与其他描述符进行匹配。记Si,j为温控余弦相似度Si,j=sim(zi,zj)/τ 。InfoNCE损失是正例对的损失的平均。
3.2.Entropy regularization
我们使用《Spreading vectors for similarity search》中提出的基于Kozachenko-Leononenko估计的微分熵损失。我们通过仅对来自不同源图像的邻居进行正则化来使其适应重复的增强设置:
L_{KoLeo}=-\frac{1}{n}log(min_{j\notin \hat P_i}||z_i-z_j||),\hat P_i=Pi \cup \lbrace i \rbrace由于这种熵损失是到最近邻居的距离的对数,因此它对附近向量的影响非常大,但当描述符相距很远时会迅速减弱。 效果是“推”开不同源图像的临近向量。
3.3.Experiment: SimCLR and entropy
在本文实验中,我们将对比损失和熵损失通过权重系数λ组合 Lbasic=LInfoNCE+λLKoLeo 。然后,我们评估组合损失对图像分类任务和复制检测人物的影响。更多详情见5.1节。
图3展示了权重系数如何影响两种任务,当熵损失权重增加时,因为这个损失对分类没有收益,ImageNet线性分类准确度降低,相反副本检测的准确率显著提升。
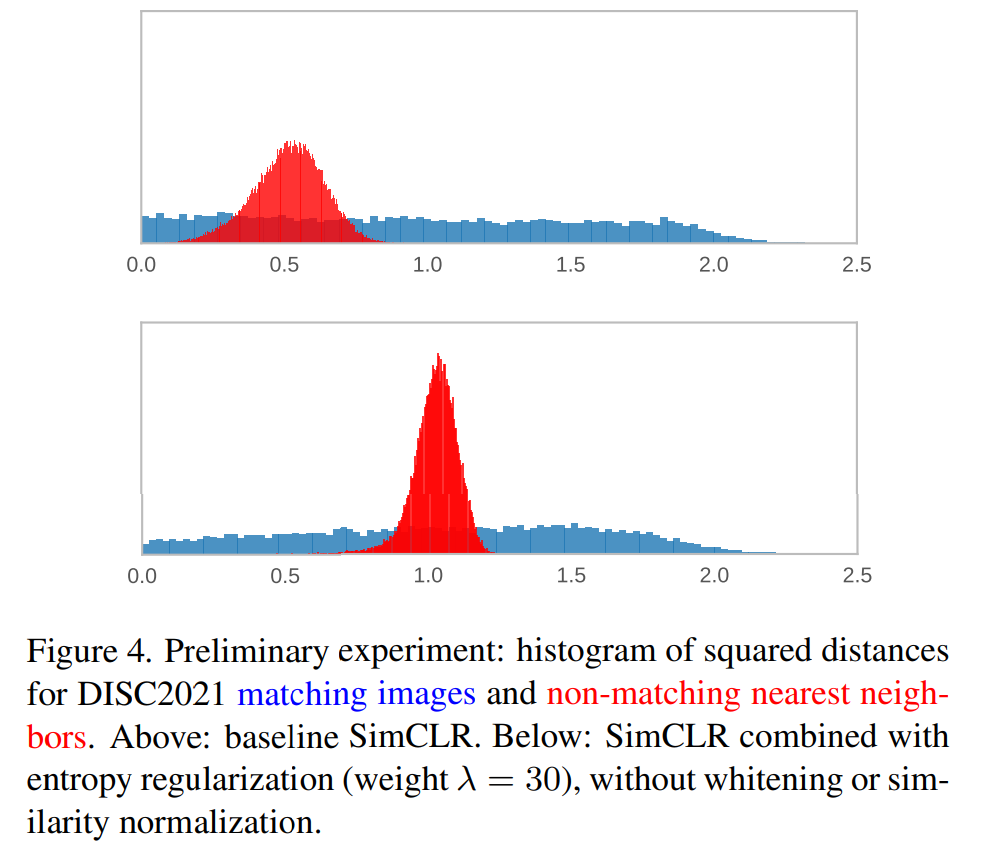
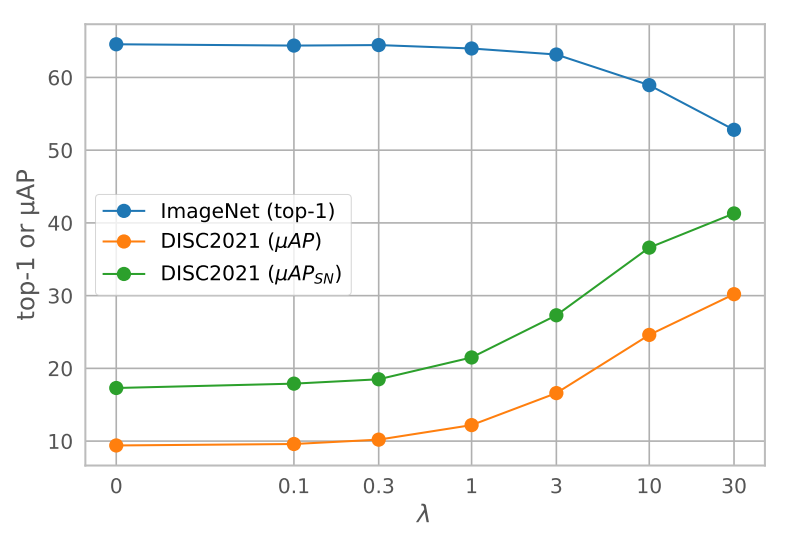
图4显示匹配图像(正对)和最近的非匹配邻居(负对)之间的距离分布。 上图是基准SimCLR,下图是SimCLR+熵损失。使用熵损失会增加所有距离并使负距离分布更窄。 结果是正对和负分布模式之间有更大的对比,即它们更清楚地分开。
4.Method
了解了熵损失如何提高副本检测精度后,在本节中,我们将其扩展为一种稳健的图像副本检测方法:SSCD。 这需要调整架构、数据扩充、池化和添加规范化阶段,如图 1 所示。
4.1.Architecture
SSCD使用ResNet-50卷积干线来提取图像特征。我们对这种架构进行了标准化,因为它被广泛使用,优化良好,并且在图像分类方面仍然非常有竞争力,但可以使用任何CNN或 Transformer 主干(参见第5节)。
池化:对于分类, CNN的最后一个激活层通过均值池化将特征转换为向量。我们改用广义均值 (GeM) 池化,[7, 39] 显示它可以提高描述符的判别能力。这对于实例检索和我们的复制检测案例都是有益的。GeM 引入了一个参数p,当 p=1 时相当于 average pooling,当 p→∞ 时相当于 max-pooling。SSCD 使用 p=3,遵循图像检索模型的常见做法。
虽然推理时的 GeM 池化系统性地提高了准确性,但我们观察到它在训练时只能与微分熵正则化相结合才有好处,因此对于普通的 InfoNCE,最好使用平均池化进行训练。我们推测 GeM 池可以降低训练任务的难度,而无需最大限度分离向量点的额外目标。我们观察到,如[39]中提出的那样,学习标量p在对比学习上是失败的:池化参数p无限增长,最终训练变得数值不稳定。
描述符投影:SimCLR 在训练时使用2层MLP投影。在推理时MLP被丢弃,直接使用CNN主干特征。尽管训练任务需要变换不变性的描述符,MLP在基础网络中仍有可能保留变换协变特征,这对下游任务可能有用。Jing还发现MLP将主干模型从InfoNCE损失引起的特征坍塌至低维空间中隔离出来。
对于 SSCD,训练和推理任务是相同的,这避免了对变换协变特征的需要。并使用微分熵正则化防止维度崩溃。我们将 MLP 替换为目标描述符大小的简单线性投影,并保留此投影以进行推理。
4.2.Data Augmentation
自监督对比目标在图像变换中学习匹配图像。这些方法对训练时的图像增强方式很敏感,因为这些变换的不变性是唯一的监督信号。
表1列出了本文实验中用到的图像增强方式。请注意,由于主要验证数据集内含有部分已被增强的数据,是否覆盖这类增强是一个挑战。
(1)DISC2021 的增强方法不完全明确;
(2)我们展示使用简单模糊增强训练的强结果。
我们的起始基线是SimCLR默认使用的增强方法。

Strong blur:强模糊在副本检测任务上的效果优于对比学习任务,相比SimCLR我们加强了模糊增强。我们发现对模糊的不变性表现在低频偏差上,降低了模型对现实世界副本高频噪声的敏感性。我们在大多数消融实验中使用了这个设定,因为它易于重现并为对比方法提供了良好的基准。这个增强方法最初是在专有数据集上调整的,不太可能过拟合DISC2021。
Advanced augmentations:本文使用额外增强来评估我们的方法,展示SSCD如何随着增强的添加而提升。一半的旋转为旋转90度的倍数,一半不受约束。文本有随机的字体、文本、不透明度、字体大小和颜色。我们增加随机尺寸的emoji。我们应用随机压缩质量的JPEG压缩。这些增强在一定程度上受到DISC2021的启发,但对于图像复制检测问题也相当通用。
Mixed images:我们在一个训练批次中使用两种增强方式增强两张图片并将其合并。在复制检测任务中,增强副本的局部使一张图像的局部包含在合成图像中。Mixup是两张图片的加权平均。CutMix将一张图像的矩形区域移动到另一张图像。混合图像在一个批次中能匹配到多张图片,需要我们修改损失函数。
4.3. Loss Functions
SSCD使用对比InfoNCE和熵损失的加权组合,我们需要为混合图像增强情况调整这两种损失,因为Pi可能包含多个匹配图像。
InfoNCE with MixUp/CutMix augmentations:我们调整InfoNCE损失以适应混合来自多个图像的特征的增强。给定图像i,有完全或部分匹配j∈Pi的,我们将等式(1)中的成对损失项修改为:
l_{i,j} = -log\frac{exp(s_{i,j})}{exp(s_{i,j})+\sum_{k\notin \hat P_i}exp(s_{i,k})},\hat P_i=Pi \cup \lbrace i \rbrace然后我们通过取每张图像的均值来组合这些项目,因此每张图像对整体损失相同,并将每张图片的损失平均化。请注意,这等价于非混合图像的InfoNCE。
Entropy loss: 与等式(3)保持一致,使Pi包含多张匹配图像。
L_{InfoNCE}=\frac 1 {2N}\sum _{i=1}^{2N} \frac{1}{|P_i|}\sum _{j∈P_i} l_{i,j}Combination:保持不变。
Multi-GPU implementation:对比匹配任务受益于大批量,因为这提供了更强的负样本。 在跨 GPU 聚合图像描述符后,在全局批次上评估损失。 来自所有 GPU 的描述符都包含在 InfoNCE 匹配的负例中,我们从全局批次中选择最近的邻居进行熵正则化。 批归一化统计数据在 GPU 之间同步,以避免在批次内丢失信息。 我们在大批量下使用LARS优化器进行稳定训练。
4.4.Inference and retrieval
对于推理,丢弃损失项。使用卷积主干从图像中提取特征,然后使用GeM池化、线性投影头部网络和L2规范化。然后我们对描述符应用白化。白化矩阵在DISC2021训练集上学习。描述符使用余弦相似度或与简单的L2距离进行比较。
4.5.Similarity normalization
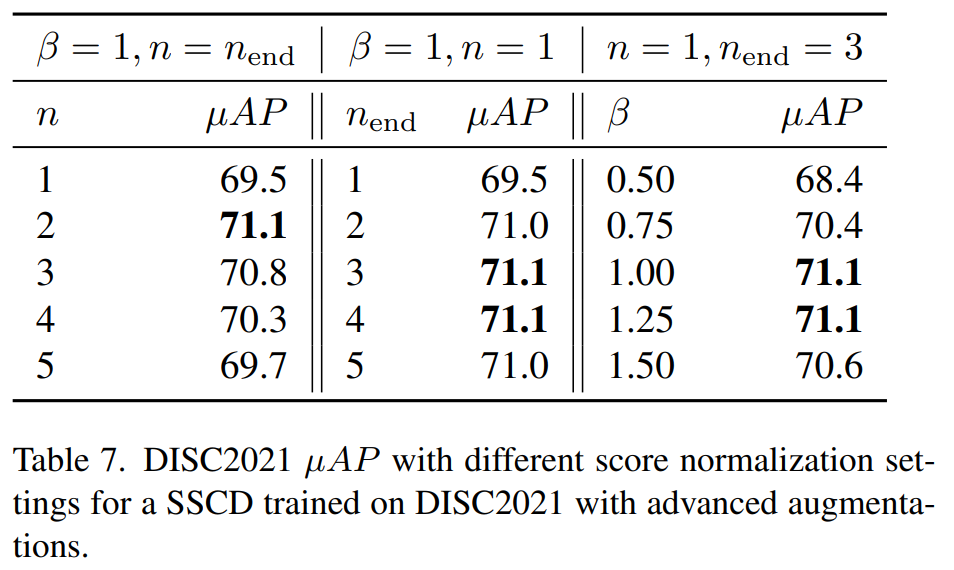
我们使用相似性归一化作为评估标准之一。它使用背景图像数据集作为噪声分布,并且仅对相似度大于与背景数据集最邻近的相似度的查询给出高分。给定查询图像q和相关图像r,相似度为s(q,r)=sim(zq, zr),调整后的相似度为s0(q, r)=s(q, r)-βs(q, bn),bn是背景数据集中第n个最近邻,β≥0是权重。我们通过从背景数据集中聚合多个最近邻(n到nend)的平均相似性来泛化(后面这部分记为bias(q)):
\hat s(q,r)=s(q,r)-\frac {β} {1+n_{end}-n}\sum_{i=n}^{n_{end}}s(q,b_i)Integrated bias:携带偏差项会使描述符的索引更加复杂。 因此,我们将偏差作为附加维度包含在描述符中。
\hat z_q = [z_q, - bias(q)],\space \hat z_r=[z_r, 1]
回看相似度的指标,由于描述符未归一化,所以点积相似度不等同于L2距离。如果索引首选L2距离,则可以使用 [5] 中的方法将最大点积搜索任务转换为 L2 搜索。
\hat s(q,r)=sim(\hat z_q,\hat z_r)
相似性归一化不断改进指标。 然而,它增加了操作的复杂性,并且可能使检测与背景分布相似的内容变得困难。 因此我们报告了有和没有这种标准化的结果。
5.Experiments
5.1.Datasets
DISC2021:参考图片100万,查询图片50000张,其中真实副本10000张。
ImageNet:预训练、对比实验用。
Copydays:小型复制检测数据集,按照常用做法,用YFCC100M的10k干扰物来增强它,称为CD10K。
5.2.Training implementation
batch size N = 4096
resolution = 224 × 224
learning rate = 0.3 × N/256
weight decay = 10−6
τ = 0.1
5.3. Evaluation protocol
我们将图像按小边等比缩放边至288。我们使用比训练时更大的推理大小来避免训练测试差异。在使用DINO ViT基线时,我们使用不同的预处理方式。
Descriptor postprocessing:图像检索受益于PCA白化,SSCD描述符先被白化,然后经过L2归一化。对于使用CNN主干特征的基线方法,我们在白化前后均进行L2归一化。SimCLR投影特征通常产生低维子空间,使得描述符大小的白化不稳定,许多时候在更小长度时的白化表现更好,因此对于基线方法,我们尝试维度{d, 3/4d, d/2, d/4, …} 并选择最大限度提高最终准确率的一个。对于SSCD,使用全描述符大小的白化。我们在DISC2021训练数据集上训练PCA,遵循该数据集的标准协议。
我们使用FAISS库进行嵌入后处理并执行繁琐的k-最近邻搜索。
5.4. Results
- 在分数归一化之前SSCD 比SimCLR uAP提高了 2 倍到 5 倍,表明复制检测受益于特定的架构和训练调整;
- SimCLR的主干特征 (µAP=13.1) 在有和没有分数归一化的情况下均优于投影头 (µAP=9.4) 的特征;
- Multigrain HOW DINO 竞赛对手方案
- SimCLR trunk 使用大模型
- SimCLR proj 投影头特征
- SimCLRCD 具有除了熵损失外的所有更改
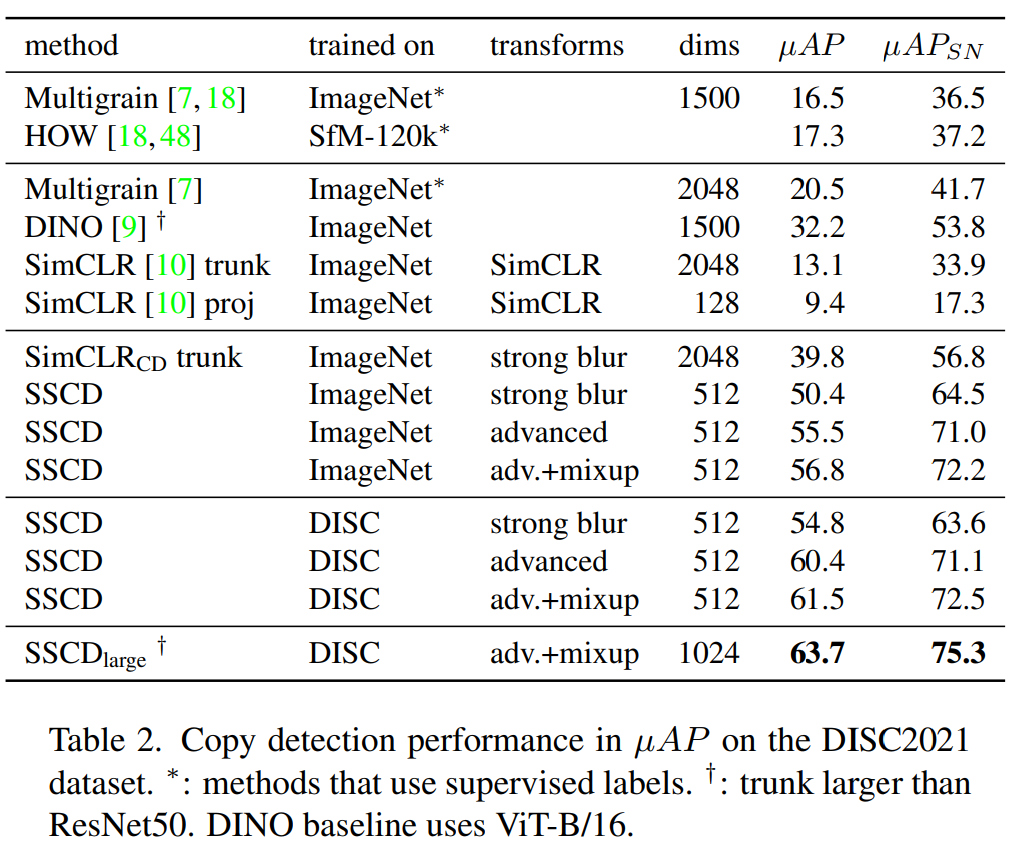
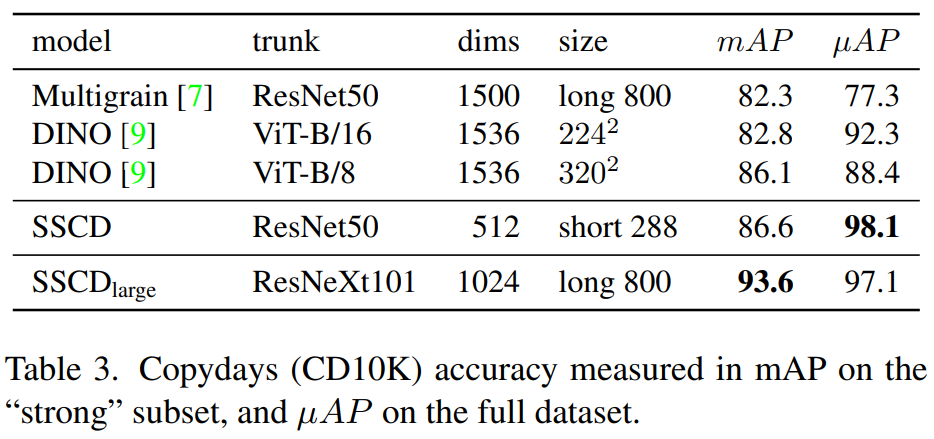
DISC results:表 2 报告了基线方法的 DISC2021 结果。我们获得了强劲的结果(第三行块)。第一个观察结果是 SSCD 在分数归一化之前将基线准确度提高了 2 倍到 5 倍,表明复制检测受益于特定的架构和训练调整。
使用我们建议的三种增强设置,展示了在 ImageNet 或 DISC2021 上训练的几个不同 SSCD 模型的结果,中间模型 SimCLRCD 具有除了熵损失外我们建议的所有更改。SSCDlarge 模型使用更大的描述符大小和 ResNeXt-101 主干。
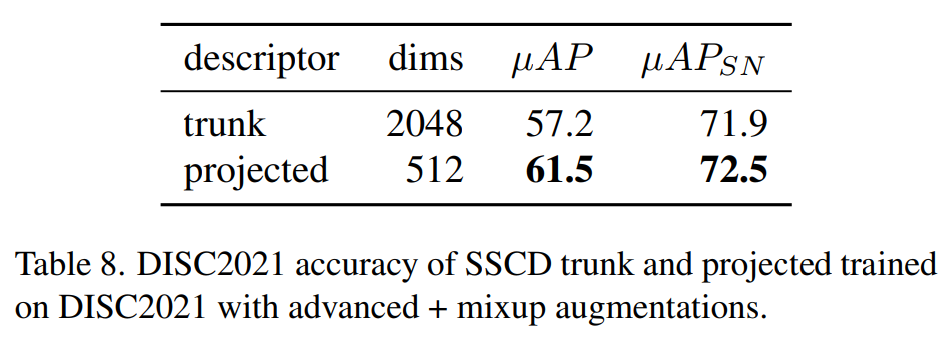
我们使用主干特征和投影特征评估 SimCLR,并发现主干特征 (µAP=13.1) 在有和没有分数归一化的情况下均优于投影头 (µAP=9.4) 的特征。进一步的实验(附录 A)在使用熵损失进行训练时显示了相反的情况:投影特征与主干特征具有相似的精度,尽管表示更紧凑。
SimCLRCD (µAP=39.8,没有分数归一化)相比 SimCLR (13.1) 的增益在第 5.5节中被解析。在 SSCD 中引入熵损失会额外绝对增加10%的µAP,通过更强的增强 (+6.2%) 和在域偏移较少的数据集上进行训练(+4.7%) 进一步增加。 这些发现在分数归一化后也能得到证实。
Copydays results:除了使用mAP测量标准外,我们的方法在全局µAP度量方面提供了显着的改进,表明有更好的距离校准。在图像检索常见的高分辨率图像上,我们观察到改进的mAP但降级的µAP。SSCD描述符比基线更紧凑。
5.5. Ablations
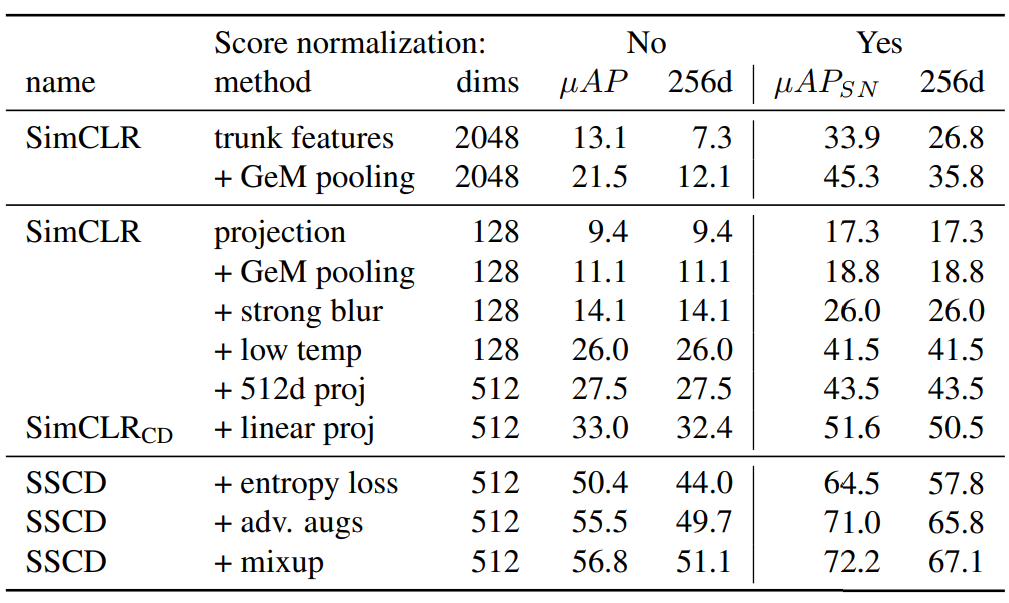
SimCLR投影向量在这项任务重并不强大,直到我们应用了几个改进;
SimCLR只能使用长度128的描述符;
SimCLRCD表示我们的架构和超参数更改;
微分熵正则化凭一己之力+17.4% µAP;
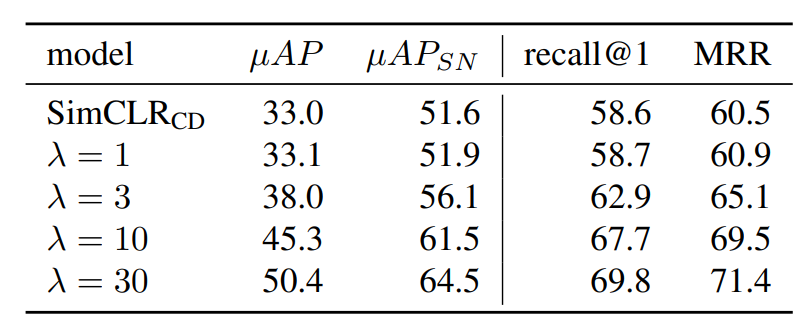
熵损失权重:随着熵权重的增加,我们看到全局准确率指标也相应增加。我们还看到查询排名指标也有类似的增加,例如recall@1和平均倒叙排名(MRR)。排名指标的增加,表明微分熵正则化创建了更统一的距离概念,总体上更提高了副本检测准确率。
与使用熵正则化的度量学习环境相比,副本检测任务受益于更高的λ值。我们的标准设置是λ=30,在λ>1时准确率降低。在λ>40时,训练变得不稳定,并且倾向于以InfoNCE损失为代价最小化熵损失:嵌入是均匀分布的,但没有意义,因为图像副本不再靠近。
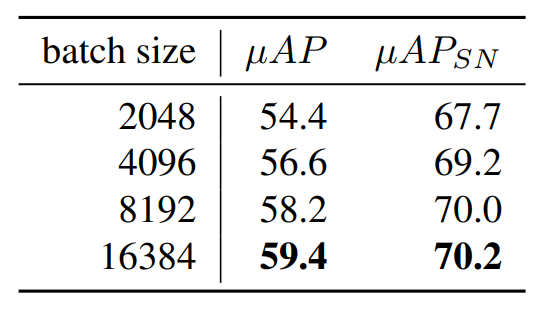
Batch size:训练目标学习在全局批处理(跨所有GPU)中匹配对。较大的批处理大小使训练任务更具挑战性,从而提高最终准确率。大批量需要用更多机器进行训练,并且由于同步批处理规范化而产生同步开销。
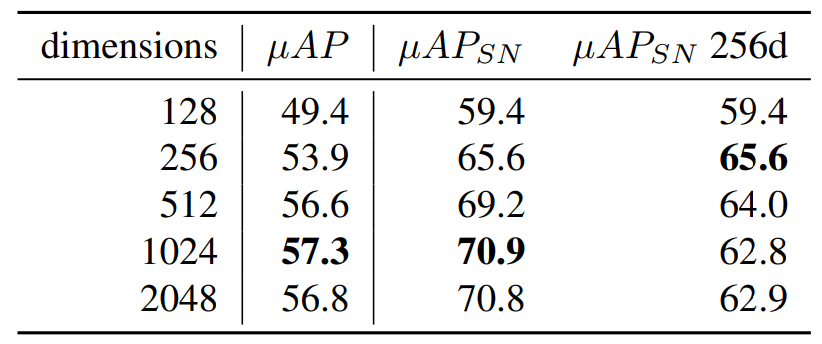
Descriptor dimensionality:描述符维度是准确率和检索步骤效率之间的权衡。当将描述符限制为256个维度进行检索时,我们看到在该大小下训练的描述符的准确率最高。
Variance between initializations:我们使用相同的设置进行训练,用五个随机种子初始化模型,发现标准差为0.2%µAP和0.1%µAPSN。
Similarity normalization settings:当使用单个邻居来规范化相似度时,使用第二个最近邻效果最好(n=2)。当在多个邻居之间使用平均相似度时,平均前2、3或4个邻居效果相似。β=1是一个很好的规范化权重。
Trunk and projected features:在推理时使用线性的投影可以提高准确率,尽管特征要紧凑得多。
6.Discussion
Dimensional collapse:当在512维中训练时,SimCLR折叠到大约256维的子空间。表4显示,当描述符大小从128维增加到512维时,SimCLR的准确率没有太大提高。SSCD的熵正则化解决了这种崩溃,并允许模型使用完整的描述符空间。
Entropy regularization and whitening:在没有白化或相似规范化的情况下,SSCD比基线更准确:在ImageNet上训练λ=30时为47.8µAP,而等效λ=0模型为26.8。熵损失和训练后PCA白化都旨在创建更均匀的描述符分布。然而,PCA白化可以扭曲训练期间学习的描述符空间,特别是当许多维度具有微不足道的方差时。微分熵则正化促进了近似均匀的空间,允许模型在训练期间适应近似白化的描述符,减少白化导致的失真。
Uniform distribution as a perceptual prior:对于这项工作中的大多数实验,我们专注于µAP指标,该指标要求在固定阈值下分离匹配和非匹配。然而,表5显示,排名指标也随着熵损失权重的增加而提高,即更好地跨查询校准并不能完全解释熵正则化的好处。
微分熵正则化充当一种先验,选择均匀分布的嵌入空间。我们认为,当应用于对比学习时,这种正则化是一种感知先验,选择更强的复制检测表示。理想的复制检测描述符将同一图像的副本映射在一起,同时保持语义相似(相同的“类”)的图像相距甚远,即描述符分布是均匀的。这不同于迁移学习到分类的表示的理想属性,即描绘同一类的图像应该在附近(密集区域),并且很好地分隔其他类(类之间的稀疏区域)。
Visual results:图2显示了一些检索结果,其中SSCD优于普通的SimCLR。前两个示例展示了在训练时更合适的数据增强的影响:SSCD忽略文本覆盖和模糊/颜色平衡。最后两个示例显示,当SSCD正确恢复源图像时,SimCLR会退回到低级纹理匹配。
Limitations:我们的方法即使使用了文本增强进行训练也是文本不敏感的,我们发现即使在没有文本增强的情况下进行训练,它也有些文本不敏感。出于这个原因,SSCD在匹配完全由文本组成的图像时并不精确。同一场景(例如地标)的不同照片可能会被识别为副本,即使照片是不同的。有时,图像被组合以创建合成图像或拼贴画,其中复制的内容可能只占据合成图像的一小部分区域。这种“部分”副本很难用像SSCD这样的全局描述符模型检测到,在这种情况下可能需要局部描述符方法。最后,高查准率/精确度的匹配通常需要额外的验证步骤。
Ethical considerations:我们将研究重点放在DISC2021数据集上,该数据集在处理人物图像方面经过深思熟虑,仅使用同意将其图像用于研究的付费演员的可识别照片。用于内容审核的复制检测是对抗性的。针对该问题发布研究可能会更好地告知旨在逃避检测的参与者。我们认为,这是开放研究将带来的改进的代价。这项技术允许标定手动审核,这有助于保护用户远离有害内容。然而,它也可以用于例如政治审查。我们仍然认为推进这项技术是一个净收益。
7.Conclusion
我们提出了一种训练有效图像复制检测模型的方法。 我们展示了使对比学习适应复制检测的架构和目标变化。 我们发现微分熵正则化显着提高了复制检测的准确性,促进了图像描述符的一致分离。 我们的方法在 DISC2021 上展示了强大的结果,显著超过基准,在 Copydays上也达到了最先进的结果。 我们的方法之所以高效,是因为它依赖于标准主干,使用比图像检索的典型推理尺寸更小的推理尺寸,并生成紧凑的描述符。 此外,在验证时可通过距离测量限制候选者。 我们相信这些结果证明了均匀嵌入分布与复制检测任务之间的独特兼容性。


![[翻译] Adaptive Pooling in Multi-Instance Learning for Web Video Annotation](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)