Multi-modal Fusion Transformer for Video Retrieval
Abstract
从视频数据中进行多模态学习最近受到了越来越多的关注,因为它允许在没有人工注释的情况下训练语义上有意义的嵌入,从而实现零镜头检索和动作定位等任务。在这项工作中,我们提出了一个多模态、模态无关的融合Transformer,它学习在视频、音频和文本等多种模态之间交换信息,并将它们集成到一个融合的多模态嵌入空间中的融合表示中。我们建议在一次训练系统时对所有内容进行组合损失——输入模态的任何组合,如单模态和模态对,明确省略任何附加组件,如位置或模态编码。在测试时,生成的模型可以处理和融合任意数量的输入模式。此外,Transformer的隐含属性允许处理不同长度的输入。为了评估所提出的方法,我们在大规模HowTo100M数据集上训练模型,并在四个具有挑战性的基准数据集上评估生成的嵌入空间,这些数据集在零镜头视频检索和零镜头视频动作定位方面获得业内最佳表现。
Introduction
人类以各种方式捕捉他们的世界,结合不同的感官输入方式,如视觉、声音、触觉等,以理解他们的环境。视频数据通过将视觉和音频信息组合成两个连贯互补的信号来近似这种类型的输入,这些信号可以通过文本描述得到进一步增强。因此,最近的研究已经开始探索如何利用这些不同模式的信息从这种内容中学习有意义的表示。这种系统可用于表示学习,例如,学习视频数据上的多模态嵌入空间,其中一个模态(如文本)的输入可以匹配到一个或多个其他模态(如视频和音频),从而实现基于近邻的零镜头分类或视频检索等任务。我们在本文中的工作集中在后面的问题,即有意义的多模态嵌入空间的学习。该领域的当前方法通常通过将输入投射到公共空间,并应用对比损失将共生模态嵌入在一起,来学习不同模态的编码。这些方法可以基于经典神经网络元素来学习这些编码[4,12,35,37,45],即卷积神经网络骨干和非线性投影[37]、多实例学习[35]或聚类[12]。最近还提出了基于Transformer的方法[1,10,20,32]。为了生成最终的嵌入空间,它们使用多个独立的单模态自注意力Transformer块[10,21,32],或者所有模态的单个Transformer模型[20],或者单个模态不可知Transformer[1]。在最后一种方法中,模态仍然被独立处理并逐个转发以实现单模态嵌入。至今为止,没有一个transformer模型能够适配任意给定数量的输入模态。尽管已经提出了处理多种输入模态的模态不可知变压器,如PerceiverIO[26],但它们是为学习一个潜在空间而构建的,该潜在空间可以覆盖不同领域的多个任务。但与我们的工作相比,这种情况下的潜在空间主要用于将多个输入和任务压缩在一个模型中。
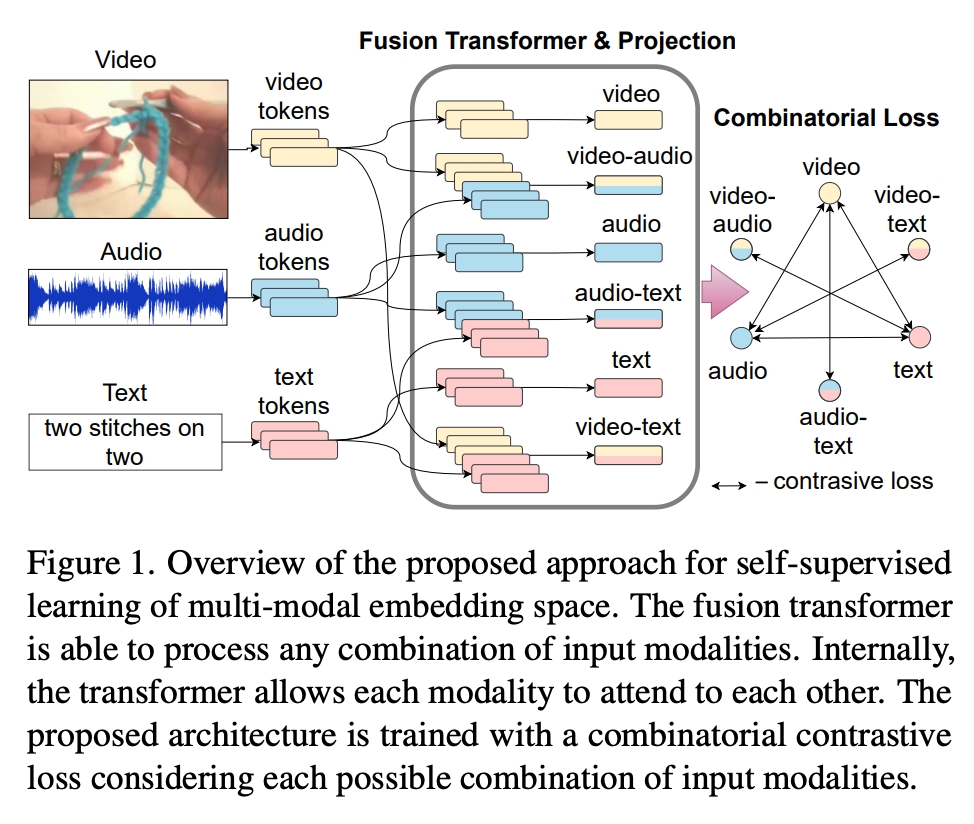
在这项工作中,我们提出了一种利用自我注意力进行多模态学习的方法,该方法组合处理任意数量的模态,并允许模态相互关注。图1显示了我们架构的高级概述。来自一个或多个模态的输入令牌,送入组合相关input得到特征的融合Transformer,然后投影到联合多模态嵌入空间。我们设计并训练融合Transformer以涵盖多模态视频学习的三个方面:首先,它应该允许模态相互关注并学习多模态相关性;第二,它应该是模态不可知的,并处理任何可能的模态输入组合;第三,由于不同的模态和样本可以在长度上有所不同,它应该能够处理任何长度的输入。为了使融合Transformer能够处理所有这些任务,我们遵循通用自注意力Transformer块的灵感,并将键、查询和值权重共享给所有标记,不知道它们的输入模态。通过这种方式,自注意力以通用方式从单一模式或任何组合模式中学习哪些输入令牌需要参与。
为了训练模型,我们提出了一个组合损失函数,它考虑了所有可能和可用输入组合之间的对比损失。例如,在视觉、文本和音频的情况下,基于每个模态嵌入的损失以及成对型的视觉-文本、音频-文本和文本-音频组合的损失,如图1所示。因此,生成的模型能够在测试时融合任意数量的输入模态。与其他通用注意力自方法相比,我们省略了任何元信息编码,如位置或模态嵌入。这进一步允许我们处理任何不同长度的输入,因为我们不再局限于训练时定义的最大输入大小。请注意,虽然我们将此网络称为Fustion Transformer,但我们并不是在提出新的Transformer架构,确切的说是指不改变自注意力机制、融合不同模态的新训练方式的Transformer。因此,最终模态可用于任何类型的输入、单一模态或多个模态的组合,以及任何输入长度。
我们在HowTo100M数据集上训练模型,并在四个下游数据集上测试其zero-shot text-to-video retrieval和step action localization来评估所提出的方法,即YouCook2[57]、MSR-VTT[54]、CrossTask[60]和Mining YouTube[29]。我们的结果表明,所提出的fusion transformer的组合方式以及组合式损失函数带来了SOTA的结果。我们总结了本文的贡献如下:
- 我们提出了一种多模态融合Transformer,它处理任意模态组合和任意模态长度的输入,并关注跨模态信息的相关特征。
- 我们提出了一种组合对比损失,考虑了训练时输入模式的所有可能组合。
- 我们发现,使用这种多模态融合Transformer作为中间处理步骤可以显着提高多模态嵌入空间学习的性能。
Related Work
多模态学习
从多个模态学习的想法可以被视为机器学习研究的一个组成部分,包括视觉语言学习[43,56]、视觉音频学习[5-7,13,23,49,52]、零试学习[25,34]、跨模态生成[33,44,58]以及多模态多任务学习[27]等领域。视频自然结合了多种模态,同时允许从在合理时间内无法注释的大规模数据中学习。在此背景下,Miech等人[37]提出了HowTo100M叙述视频数据集,并提出了一个系统,展示了多模态学习通过对比损失学习视频-文本嵌入空间的潜力。该数据集包含YouTube教学视频,这些视频带有音频和ASR生成的字幕。由于这些数据可以被认为比精选的视觉-文本数据集更嘈杂,Amrani等人[4]提出了通过多模态密度估计对多模态数据进行噪声估计。Miech等人[35]提出了MIL-NCE,将噪声对比估计的思想与多实例学习公式相结合。Alwassel等人[3]仅使用音频和视频信息,并提议利用无监督聚类作为跨模态的监督信号。虽然这些作品[3,4,35,37]仅使用两种模态来训练他们的模型,但其他人则专注于同时从视觉、音频和文本中学习的问题[2,8,12,19,45]。也许是第一个,Aytar等人[8]提出了一种基于图像-文本和图像-音频对训练的架构,允许连接文本和音频模态。后来Alayrac等人[2]遵循不同模态组合的不同嵌入空间的想法,并提出了多模态多功能网络。Rouditchenko等人提出了共享嵌入空间。[45]将所有三种模式映射在一个关节空间中。Chen等人[12]最近通过额外的聚类和重构损失扩展了这一想法。
基于Transformer的多模态学习
基于自注意力和Transformer的架构已经被探索用来从多模态视频数据中学习。程等人[15]提出了一个共同注意力模块来学习音频和视频样本之间的对应关系。罗等人[31]接受了这个想法,但提出了视频-文本对的联合跨模态编码,类似于视觉语言任务的Uniter[14]。与此相比,贝恩等人[10]专注于如何处理视频主干中的时间和空间信息的问题。因此,他们在两个独立的Transformer主干中处理视频和文本两种模态,并且只在主干顶部添加了一个线性映射层。在这种背景下,最近,Nagrani等人[39]提出了一种多模态瓶颈Transformer,用于在监督环境中训练的有效视听融合。Akbari等人[1]提出了一种基于Transformer的方法,该方法实际上使用了所有三种模态,因此可以被认为最接近我们提出的工作。在这里,单个主干Transformer分别应用于任何模态,但具有共同的注意力。对于训练,该模型遵循[2]的思想,首先计算视频-音频的匹配,然后是视频-文本匹配。因此,它以成对型的方式融合了这些模态,这可以与我们提出的损失函数的子集进行比较。其他方法也利用了多模态Transformer学习的背景下的时间概念。Gabeur等人[20]使用专家组合和时间嵌入的来训练多模态Transformer。而Wang等人[51]提出了基于多模态专家的局部-全局时间对齐来指导训练。Lou等人[32]也探索了简单地使用预训练的视觉语言Transformer模型的想法,使用预训练的CLIP模型[43]作为主干,在视觉和文本主干之上具有基于Transformer的相似性编码器,并在视频检索等任务上取得了良好的效果。由于大多数基于Transformer的方法使用各种有时不公开的数据集进行主干预训练,或者需要难以重复实验的资源,因此很难直接比较不同架构和预训练集的性能。因此,我们决定遵循这里大多数工作中使用的设置,并依赖预提取的特征,然后由提议的架构处理,以允许与以前的工作进行直接比较。
Method
我们的目标是学习单个模态或一组模态的投影函数到联合嵌入空间中,使语义相似的输入彼此接近,例如视频场景的文本描述的投影应该接近该场景的视频-音频表示的投影。在下面,我们考虑了三种模态,视频、音频和文本(对应的自动语音识别字幕或语言叙述);但是所提出的方法可以扩展到更多的模态。
3.1. Problem Statement
从数据分布中给定一组N个视频切片的文本t-视频v-音频a三元组,学习映射函数F接受最多三个输入产生d维输出,我们的目标是最大化语意相关输入之间的点积相似性,如f(t) f(v) f(a) f(t,v) f(t,v,a)之间的相似性,最小化其他情况。
3.2. Model Architecture
3.2.1 Token Creation
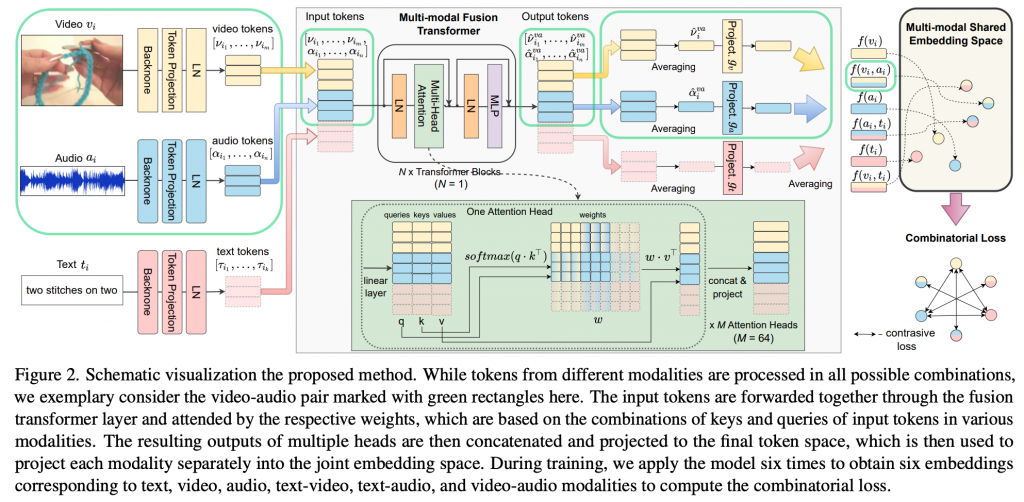
如图2所示,我们的架构从特定模态的骨干网中提取的特征开始。我们通过特定模态的可学习映射和归一化层,将提取的特征向量集转换到令牌空间。对于(ti, vi, ai)输入三元组,我们获得三组令牌:来自文本ti的[τi1,…,τik],来自视频vi的[νi1,…, νim],来自音频ai的[αi1,…,αin]。由于令牌的数量可能会有所不同,例如视频剪辑的长度不同,我们标准化每个batch输入的长度,以允许通过填充和使用注意力掩码进行批量处理作业。
3.2.2 No Positional Embeddings
与其他基于Transformer的方法[1,10,14,30,48]不同,我们省略了向Token添加任何位置或类型的嵌入信息。有三个原因,关于类型嵌入,可以假设标记已经编码了这些信息,因为它们是由不同的主干生成的,因此每个主干都有自己的“指纹”。位置信息已被证明在一致的结构化数据(如句子)的上下文中是有益的。但是在多模态视频学习的情况下,剪辑在训练时从更大的视频序列中随机采样,通常不考虑镜头边界或语音暂停。因此,我们不期望剪辑切片总是从动作开始时开始的这种时间一致的模式。因此,省略位置嵌入可能会防止在训练期间添加噪声。在推理时,避免位置嵌入允许我们输入比训练时更长的序列。
3.2.3 Multi-modal Fusion Transformer
由于我们的目标是学习输入任意数量的模态和组合的表示,我们希望投影f学习如何融合来自多个模态的信息以增强联合嵌入表示。为此,我们提出了一种多模态、模态无关的Transformer,其中输入标记的键、查询和值以及所有进一步转换的计算都独立于模态。我们的多模态Fustion Transformer,采用常规Transformer块[50]。每个Transformer块由一个多头自注意力和一个多层感知器(MLP)组成,在它们之前有两个LayerNorm(LN)变换以及两个残差连接,如图2所示。请注意Fustion Transformer与其他Transformer的区别不在于架构本身,而在于它的训练方式,以及在专门设计的训练中,普通Transformer块可以学习到融合信息的事实。因此,Fustion Transformer指的是Transformer块的使用方式,而不是新架构。
我们用所有可能的模态组合作为token输入来训练这个系统:单个t,v,a,成对的(t,v),(v,a),(t,a),允许来自一个模态的token与其他模态的token交互。这样,我们可以从多个模态中获得融合表示:组合(t,v)将产生文本和视频模态的融合表示,记为为tv,以此类推va表示视频和音频,ta表示文本和音频。注意,在四种模态的情况下,我们将在训练中考虑最多三种组合的三元组,如(t,v,a)。随着更多的模态被添加,其组合数量将超过可以组合所有情况的临界值。在这种情况下,可以在训练中使用随机模态暂退法,如AVSlowFast[52]或Percader[26]中所做的那样。
由于我们希望Fustion Transformer是模态无关的,在每次训练迭代中,我们应用它六次以获得每个元组i的六种表示:ti、 vi、 ai、 tivi、 viai、 tiai。为了获得每个表示,我们创建一个Token的组合列表,例如对于viai:[νi1,…,νim,αi1,…,αin],我们将Transformer应用于此输入并获得输出token,viai:[ˆνi1 , …, νˆim, αˆ i1 , …, αˆin ](ˆν和αˆ表示令牌同时参与了v模态和a模态),其中每个Token都融合了来自另一个Token的信息。请注意,与ViT模型[18]不同,我们没有添加通常作为所有令牌联合表示的可学习的[cls]令牌。在我们的消融研究中,发现这对模型有益(第4.4节)。
3.2.4 Projection to Shared Embedding Space
我们使用生成的输出令牌为每个模态创建最终的embedding。对于每个训练样本,我们得到六个输出令牌集,从而得到mebedding。以为viai创建表示的情况作为例子。
ˆνi=∑(ˆνi1 , …, νˆim),ˆαi = ∑(ˆαi1 , …, ˆαin )
我们在该计算中获得了包含的每个模态的向量表示。但是这些模态之间,即使混合了其他模态信息,仍然非常不同,我们通过可学习的特定模态映射方式gt、gv和ga将t、v、a分别投影到共享嵌入空间中,然后将它们归一化,再组合成最终的嵌入向量:
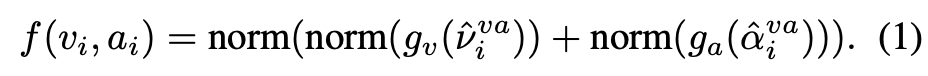
归一化用于对齐向量的大小,这样在计算点积相似度时,我们只需考虑向量之间的角度。
3.3. Combinatorial Loss
对比损失可用于学习表示,使得语义相似输入的映射彼此靠近。一些方法[1,2,12,45]通过三对单模态的对比损失L(t,v)、L(v,a)、L(t,a)的训练使模态融合,与这些方法不同,我们强制token在模态之间交换信息,同时使用额外的对比损失L(t,va)、L(v,ta)、L(a,tv)。我们的组合损失定义如下:
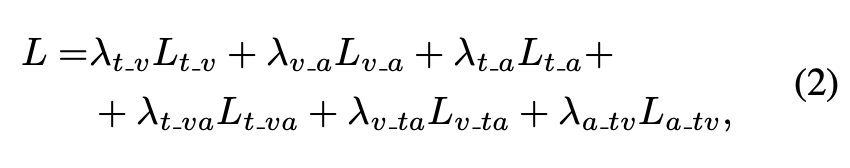
λ表示加权系数。我们的组合损失考虑了所有可能的和可用的模态组合,并且可以推广到任何一组模态。
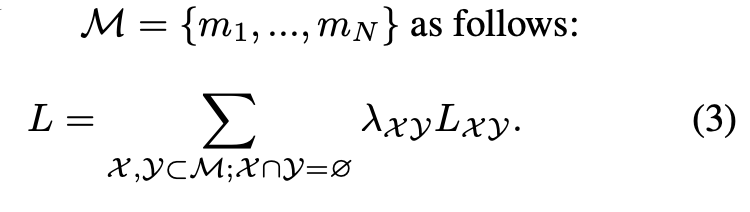
为了计算所有组合的对比损失,我们使用带有temperature τ和 batch size B的噪声对比估计[40]:
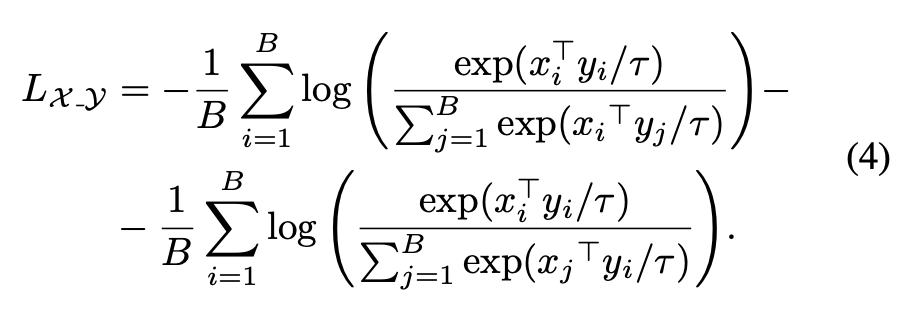
通过结合这两个方面,所有可能模态组合的处理方式和使用所提出的组合损失的系统训练,我们获得了一个多模态Fustion Transformer,它学会接受一个模态token的输入到所有其他模态的token的输入。
4. Experimental Evaluation
4.1. Experimental Setup
Backbone
视觉骨干模型:使用ResNet-152[24],在Imagenet上预训练计算2D特征(2048维,每秒一个),使用ResNeXt101[22]在Kinetics上预训练计算3D特征(2048维,每1.5秒一个)。用最近临在时间维度上采样2D特征使其与3D特征数量相同,然后将它们连接起来以获得4096维向量。
文本骨干模型:GoogleNews预训练的Word2vec模型[38]使用每个单词300维的嵌入。这些主干是固定的,在训练期间没有微调。
音频骨干模型:按照[12,45],我们使用带有残差层的可训练CNN作为音频主干,并调整最后两个残差层以每秒提取1.5 4096维特征(参见补充材料)。
Data Sampling
我们一个batch使用224个视频,每个视频随机采样十个8秒的剪辑。如果采样的剪辑包含旁白(占所有剪辑的95%),我们使用ASR识别时间戳来选择剪辑边界。为了防止HowTo100M中非常高的文本-音频相关系数的干扰,并避免文本被学习为音频旁白,相对于视频和文本边界,我们将音频剪辑点随机移动4秒。
Projections
如[12,37,45],我们使用门控线性的投影[36]将特征投射到公共令牌空间,并将生成的令牌投射到共享嵌入空间。我们将公共令牌空间的维度设置为4096,共享嵌入空间的维度设置为6144。
Transformer architecture
作为多模态融合Transformer,我们使用一个hidden size=4096、head=64,MLP=4096的Transformer块。
Loss computation
我们在NCE中使用0.05的温度,并在计算点积之前对向量进行归一化。由于不是每个视频剪辑都具有所有三种模式,我们仅在非空嵌入上计算NCE。与[2]相同,我们为公式2中的文本视觉损失设置了更大的权重,因为它有利于在HowTo100M上训练:λ(t, v)=1,λ(v, a)=λ(t, a)=λ(t, va)=λ(v, ta)=λ(a, tv)=0.1
Optimization
Adam optimizer
lr=5e-5
exponential decay=0.9
4.2. Datasets, Tasks, and Metrics
4.3. Comparison with State-of-the-art
4.4. Ablation Studies
Impact of fusion components
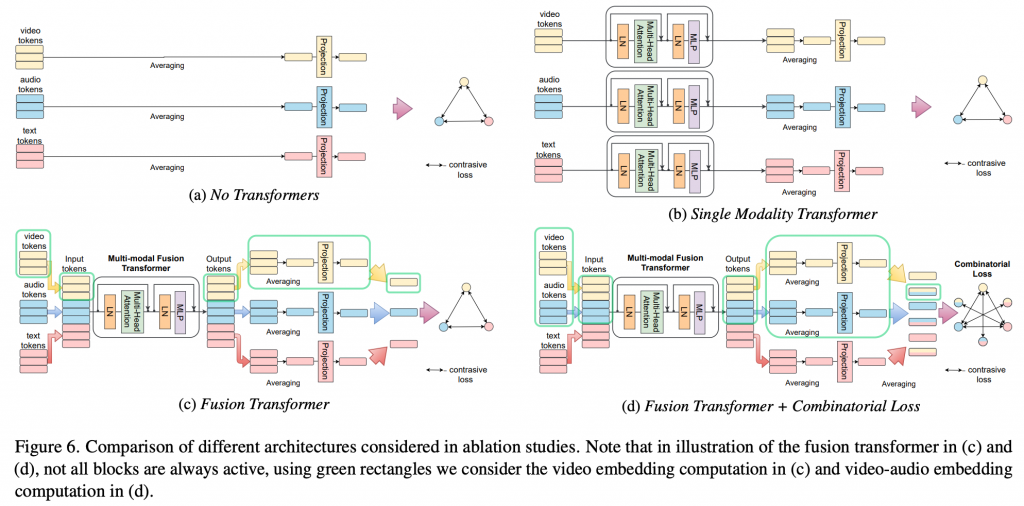
我们依次讨论提出的组件:Transformer层、Transformer融合和组合损失如何影响我们系统的整体性能。在表4中,我们考虑了以下架构,如图6: 1)无Transformer:我们的架构没有Transformer,只有三个成对的对比损失;2)单模态Transformer:使用三个独立的模态特定Transformer层来学习三个投影函数;3)融合Transformer:使用提议的模态不可知Transformer,但在没有融合模态组件的情况下使用三个成对的对比损失进行训练;4)融合Transformer+组合损失:使用提议的模态不可知Transformer组合输入,使用组合损失进行训练。我们进一步考虑了组合两种模式的两种方法,第一种通过独立计算它们并将两个输出相加(v+a),第二种一起计算他们(va)。总体而言,我们观察到添加一个简单的Transformer来单独处理每个模态已经比基线显著提高了性能,尤其是对于YouCook2数据集。我们进一步观察到,总体性能取决于测试时模型、损失函数和融合策略的组合。虽然Transformer的Token融合总体上是有益的,但Fustion Transformer+组合损失是最佳。当单独使用融合Transformer时,与单模态Transformer相比,性能略有下降。然而,利用具有组合损失的共享Transformer来融合来自不同模态的Token优于单模态Transformer的模态相加。

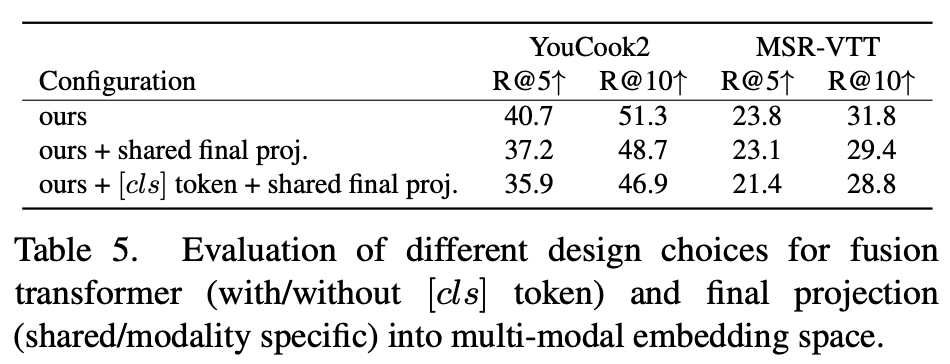
Token Aggregation and Projection
与聚合[cls]令牌中的信息相比,我们进一步评估了单独处理输出令牌的影响。为此,我们将我们的模型架构与具有共享最终投影的设置以及具有附加[cls]输入令牌的设置(类似于BERT[17])进行比较。在最后一个场景中,我们使用多模态融合Transformer的输出[cls]作为输入令牌的聚合表示,并应用最终共享投影将其映射到共享嵌入空间。如表5所示,我们没有[cls]令牌的特定模态投影比两个数据集中的其他选项更有利。
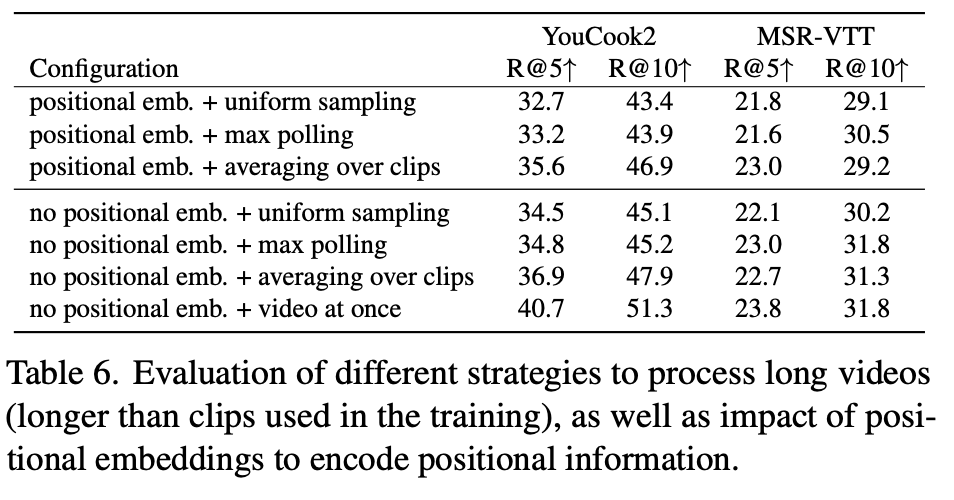
Positional Embedding and Testing on Longer Clips
最后,我们讨论了随机长度输入选项如何影响模型在测试时的整体性能的问题。我们考虑了对较长剪辑进行测试的四种不同场景,如表6所示:1)均匀采样——从骨干获得初始局部特征后,对特征进行均匀采样来适配标记的最大数量;2)最大池化——使用自适应最大池化合并初始局部特征;3)将较长的切片剪辑为训练时间长度的切片,并将得到的表示取均值;4)视频一次处理所有特征。我们进一步在前三个场景中比较了有位置嵌入和没有位置嵌入的结果。作为位置嵌入,我们使用了可训练嵌入[17],that are summed up to the input tokens before being input to the transformer。它表明在两个数据集上,具有位置嵌入的设置始终低于没有位置嵌入的设置。查看不同处理策略的结果,我们发现我们的模型与最大池化、均匀采样相比受益于利用数据中的本地时间依赖性,通过将视频剪辑切片为较短的剪辑或视频。此外,一次性利用视频中的所有输入数据进一步显著提高了性能。
Attention Analysis
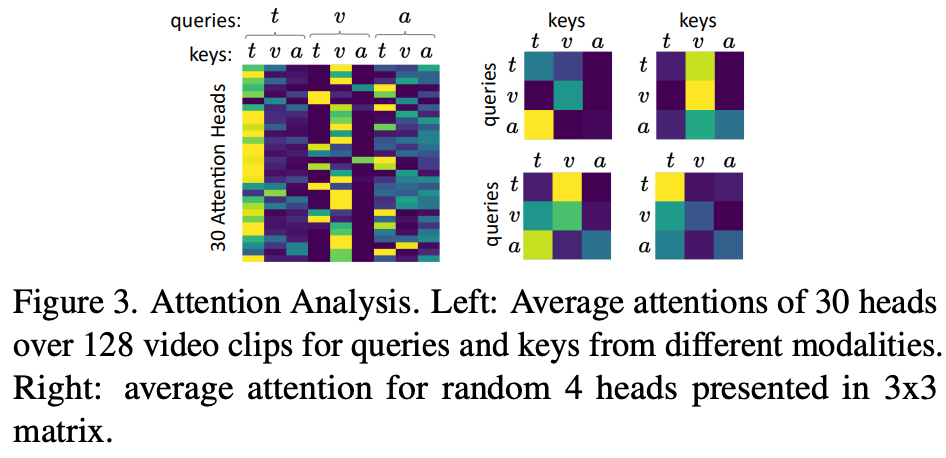
最后,我们定性分析了我们的多模态Transformer的融合能力。在图3中,我们展示了对来自不同模态的查询键对标记的平均注意力。我们观察到一些头部对单模态融合有很强的关注,主要是对t和v模态,在这两者之间,一些头部负责跨模态的关注。
Limitations and Conclusion
在这项工作中,我们提出了一种多模态、模态无关的融合Transformer方法,该方法学习在多种模态(如视频、音频和文本)之间交换信息,并将它们集成到一个联合的多模态表示中。我们发现在任何可能的模态组合上使用组合损失训练系统能使融合Transformer学到一个强大的多模态嵌入空间,而无需任何附加组件(如位置编码)。当观察两个下游数据集YouCook2和MSR-VTT的性能差异时,能看到明显的系统局限性,表明更好的融合会导致以不同方式获取的多模态数据的泛化性损失。未来减轻这些影响的研究方向可能是考虑多模态零镜头识别背景下的域适配或泛化技术。我们希望所提议的设置可能会激发对这一主题以及基于自注意力的多模态视频处理的进一步研究。
![[翻译] RetinaNet: Focal Loss for Dense Object Detection](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)