See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification
Abstract
数据增强一般用来增加训练数据数量,防止过拟合并提升模型效果。然而在实际中,随机数据增强尤其是ramdom cropping很低效同时会引入不可控的背景噪声。本文提出弱监督图像增强网络(WS-DAN)探索数据增强的潜力。对于每张训练图像,首先使用弱监督学习生成注意力热图表示目标有辨识力的部位,然后使用attention crop和attention drop等方法在注意力热图的指导下进行图像增强。WS-DAN在两个方面增强了图像分类的准确性,(1)由于提取出有辨识力的部位,网络可以更好的关注图像特征;(2)注意力热图提供了物体的准确位置,可以让模型更近的关注物体来提升效果。在细粒度视觉分类数据集上的综合实验表明WS-DAN超越了SOTA,证明了其有效性。
Introduction
数据增强通过提升样本多样性增加训练数据数量,提升模型表现,并在多个领域被证明有效,如目标检测、分类、分割。数据增强有多种方式,比如裁剪、旋转、颜色增强。之前的工作一般选择随机增强……
细粒度视觉分类(FGVC)旨在将基本类别进一步细分,例如鸟的种类、车型、飞机型号。FGVC在主要有三大难点,(1)类内差异大,同一类别的目标表现出
显著不同的姿态和视角;(2)类间差异小,不同种类的目标可能除了细微地方有差异外非常相似,例如鸟头部的不同颜色决定了它的种类;(3)训练数据有限,细粒度分类一般需要相关领域知识和大量标注时间。目前SOTA的粗粒度分类方法,CNN、VGG、ResNet等,难以达到高准确率。
……
本文的主要贡献有:
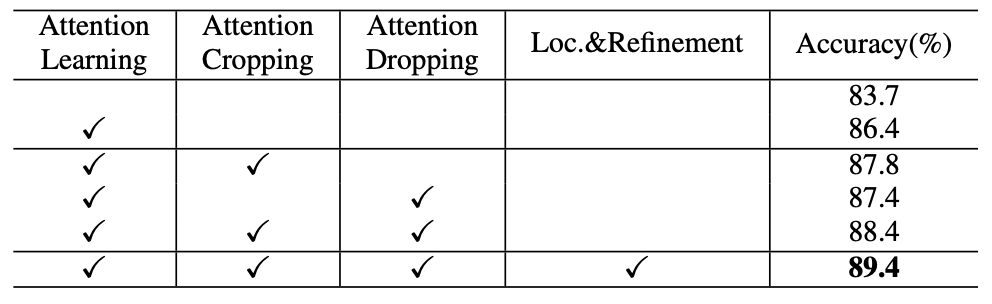
- 提出若监督注意力学习来生成注意力热图,表示目标显著部位的空间分布,并提取连续的局部特征解决细粒度视觉分类问题
- 基于注意力热图,提出两种注意力指导的数据增强方法提升数据增强效果。attention cropping随机裁剪并缩放注意力热图的一个局部来增强局部特征表达,attention dropping随机擦除注意力热图的一个局部来增强模型从多个显著位置组合特征的能力。
- 利用注意力图来准确定位目标,并将其放大以进一步提高分类精度
Related Works
2.1 Fine-grained Visual Classification
卷积神经网络的骨干网络只能解决大规模图像分类问题,不经过特殊设计很难专注于对象的细微差别,因此也只能达到一般效果。目前已经有很多的弱监督方法专注局部特征,大部分依赖局部区域的标注。
Part RCNN 检测物体并在几何先验条件下定位局部,然后使用姿势归一化表达预测细粒度分类;Deep LAC使用反馈控制框架对齐反向传播,并局部化分类错误,还提出了阀联动功能(VLF)以连接定位和分类模块。
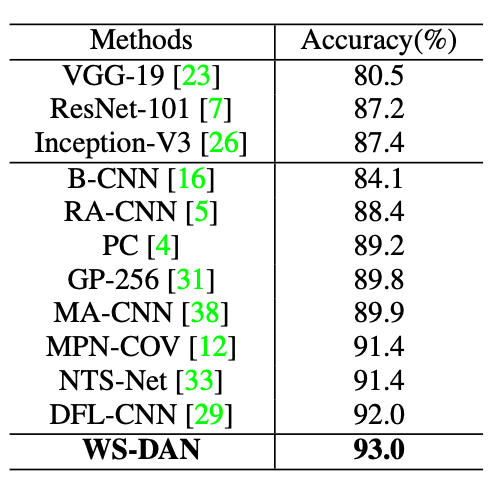
为了降低额外位置标注的花费,仅使用图像级标注的方法收到更多追捧,并已经提出一些特征池化方法。Lin提出并改进了bilinear pooling;MPN-COV改进了second-order pooling并达到SOTA;STCNN旨在首先学习合适的视觉几何变换,然后再分类,其支持同时定位多个目标区域;RA-CNN递归获取关注区域,提取相关特征并预测,因为这个方法每次聚焦一个局部,所以作者组合三个不同尺度或三个部位的特征预测最终结果;MA-CNN同时关注多个目标局部。这些方法提出通道组合损失,使用聚类生成多个局部,但目标局部的数量是有限的(2或4),因此影响了正确率。本文提出bilinear attention pooling,组合注意力层和特征层,这使得注意力区域能够轻易增加提高模型效果。
FGVC中也使用了度量学习,MAMC loss 将正例特征拉近到锚点并将负例推远;PC结合成对的混淆损失和交叉熵损失,以更广泛的学习特征防止过拟合。本文使用注意力正则化损失来规范注意力区域校正局部特征,提高了目标局部的识别率和分类准确性。
2.2 Data Augmentation
Max-drop 旨在删掉最大激活的特征区域,促使网络学习不显著的特征,但它只能删掉一个区域,因此被限制了能力;Cutout和Hide-and-Seek通过在训练集上随机覆盖许多正方形区域提高模型鲁棒性,但删除的区域很多事不相关的背景或目标的全部特征,尤其是小目标。
随机数据增强效率低且会生成大量不受控制的噪声数据,为了解决这些问题,一些方法将数据分布纳入考虑,这比随机增强方法更有效。AutoAugmentation创建了数据增强策略的搜索空间,可以自动设计特定方法在目标数据集上使验证集达到SOTA;Adversarial Data Augmentation 使用对抗性数据增强共同优化数据增强和深层模型,设计生成网络在线产生难样本提高模型鲁棒性,但这种对特定数据的增强方法比随机增强复杂得多,本文的方法更简单,并可以生成局部增强来提高性能。
2.3 Weakly Supervised Learning for Localization
(略)
Approach

3.1 Weakly Supervised Attention Learning
3.1.1 Spatial Representation
我们提出注意力热图来表示目标区域而不是SS或者RPN,这样更加灵活并可以端到端训练。首先预测目标的多个局部位置,然后将裁剪多个局部图像,计算特征,组合多个特征,输出结果。
3.1.2 Bilinear Attention Pooling

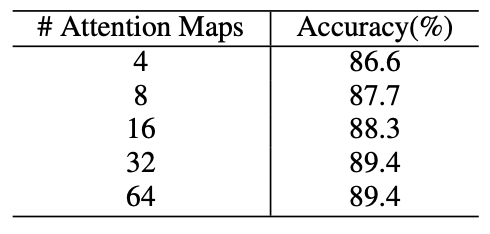
- 骨干模型输出特征图和注意力图,每张注意力图表示一个目标局部
- 将特征图和每张注意力图点积得到多张局部特征图
- 将每张局部特征图池化过卷积至一维
- 组合所有局部特征
3.1.3 Attention Regularization
我们期望注意力热图Ak能表示目标的第k个局部,受到center loss的启发,我们提出注意力归一化损失对这个过程进行弱监督。我们惩罚属于目标相同局部特征的不同表达,使得局部特征fk趋近于特征中心ck,注意力热图Ak将在相同的局部被激活。(文章假设每张注意力热图对应一个类别的一个局部,因此限制了类别数量或局部个数)
3.2 Attention-guided Data Augmentation
3.2.1 Augmentation Map
对于每张训练图像,随机选择一个它的注意力热图Ak,将其归一化后,用于指导数据增强。
A_k^* = cfrac{A_k - min(A_k)}{max(A_k)-min(A_k)}
3.2.2 Attention Cropping
将注意力热图Ak*上大于阈值θ的点置为1,其余置0,得到Ck;在Ck上搜索一个bbox使其包含所有值为1的点,将bbox坐标放大至原图,执行裁剪。
3.2.3 Attention Dropping
将注意力热图Ak*上大于阈值θ的点置0,其余置1,得到Dk,放大至原图进行色块丢弃。
3.3 Object Localization and Refinement
注意力指导的数据增强也可以用到之前弱监督注意力学习过程中,使目标区域被预测的更准确。在推理阶段,模型输出粗粒度分类结果和原始图片的注意力热图,可以用来预测目标位置,将目标放大并再次经过网络得到微调结果。最终分类结果是粗粒度预测和细粒度预测的均值,详细描述见伪代码:
- 模型输出粗粒度概率p1 和注意力热图A
- 注意力热图A取均值得到 A_m = cfrac{1)}{M)}A
- 从Am中获得bbox B
- 将B拉伸至原图尺寸,送入模型
- 模型输出细粒度概率p2
- p=(p1+p2)/2
Experiments


Conclusion
WS-DAN达到了SOTA!
![[翻译] UNITER:通用图文表示学习](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)