Abstract
最近大型语言模型(LLMs)的进展,如GPT4,在遵循给定图像的开放式指令方面展示了出色的多模态能力。然而,这些模型的性能严重依赖于设计选择,如网络结构、训练数据和训练策略,而这些选择在文献中尚未广泛讨论,使得难以量化该领域的进展。为了解决这个问题,本文对这些模型的训练进行了系统和全面的定量和定性研究。我们实现了超过20个带有控制设置的变体。具体而言,对于网络结构,我们比较了不同的LLM骨干和模型设计。对于训练数据,我们调查了数据和采样策略的影响。对于指令,我们探索了多样化提示对训练模型的指令遵循能力的影响。对于基准测试,我们通过众包贡献了第一个综合评估集,包括图像和视频任务。基于我们的发现,我们提出了Lynx,它在保持最佳多模态生成能力的同时,执行最准确的多模态理解,与现有的开源GPT4风格模型相比。
1. Introduction
使用指令微调[7, 4, 14 – 17],LLMs可以进一步遵循非专家用户的开放式指令,并作为我们的日常生活中的基于对话的助手。利用强大的LLMs,最近的研究已经探讨了将LLMs适应于多模态输入(例如图像[18-24]、视频[19(Flamingo)、21、25-29(Videollm, Video-chatgpt, Video-llama)]和音频[29、30(audiogpt)])和输出(例如视觉任务[31 Visionllm]和机器人操作技能[32-34])的方法。值得注意的是,GPT4以其令人印象深刻的稳定的零-shot多功能实用能力,例如在给定图像的情况下生成描述、故事、诗歌、广告和代码等方面,令世界为之震撼,这在以前的视觉语言模型中很少见到[18,35-39]。
然而,GPT4如何获得其令人印象深刻的智能仍然是一个谜。尽管最近积极调查,但现有模型通常在网络结构、训练数据、训练配方、提示和评估基准方面有所不同,这使得极难确定哪些因素对于实现高性能多模式语言模型至关重要。此外,缺乏适当的定量基准来评估和比较这些模型,使得难以归因和量化开源多模式LLM的进展。
因此,在本文中,我们进行了系统研究,培训GPT4风格的模型以解决上述问题。根据现有文献,我们确定了实现多模式LLM高性能的三个可能关键因素:网络结构、训练数据和多样化指令。关于网络结构,我们探索了不同的LLM适应策略,包括带有多模态适配的[?23,22]广泛使用的基于交叉注意力的结构[19]和最近流行的仅解码器结构。此外,我们调查了不同的骨干,包括LLaMA-7B和Vicuna-7B,以评估语言指令微调是否影响最终的多模式性能。对于训练数据,我们尝试了几个大规模数据集(例如COYO700M [40]、DataComp1B [41]和BlipCapFilt [39]),这些数据集由图像文本对组成,以观察不同数据组合的影响。对于指令,我们为每个任务手动标记至少三个提示,并使用GPT4生成更多提示,以确定语言提示的多样性对结果的影响。总共有500个提示,涵盖50多个任务。总之,我们通过控制变量设置实现了约20个变体,并进行了广泛的实验,以从定量和定性两方面得出可靠的结论。
为了进行基准测试,我们认为多模态LLMs的评估与典型的视觉语言方法本质上不同。评估类似于GPT4风格的模型时的主要挑战是平衡文本生成能力和多模态理解准确性。为了解决这个问题,我们提出了一个新的基准,结合视频和图像数据来评估多模态理解和文本生成性能。使用我们提出的基准,我们评估了大量的开源方法并提供了全面的评估。具体而言,我们采用了两种定量评估协议。首先,我们收集了一个开放式视觉问答(Open-VQA)测试集,包括关于对象、OCR、计数、推理、动作识别、时间顺序等问题。与标准的VQA [42,43] 不同,Open-VQA中的答案是开放式的。为了评估在Open-VQA上的表现,我们提示GPT4将其作为鉴别器,得到了与人类评估的95%一致性。这个基准用于评估所有模型的准确性。此外,我们采用了mPLUG-owl [22] 提出的OwlEval测试集来评估给定图像的文本生成能力。尽管OwlEval只包含82个基于50个图像的问题,但它涵盖了各种任务,如生成描述、故事、诗歌、广告、代码和其他复杂而实用的给定图像的分析。在这部分中,我们招募人类注释者来排名不同的模型。
根据我们对受控实验的广泛分析,我们的发现可以总结如下:
- 在使LLMs适配多模态输入方面,使用可训练适配器的前缀预训练比交叉注意力表现更好。
- 数据质量比数量更重要。我们发现,使用大规模图像文本对(如COYO700M和DataComp1B)训练的模型不如使用小但高质量数据集训练的模型更好地生成语言,因为它们可能会污染输出分布。
- 多样化的提示对于提高指令遵循能力和最终表现至关重要。
- 对于LLMs适配多模态,仔细平衡多模态理解和文本生成能力至关重要。基于指令微调模型(如Vicuna)的多模态适配可以提高指令遵循能力。
通过我们的研究,我们提出了Lynx,这是一个简单的前缀调整GPT4风格的模型,采用两阶段训练配方。对于第一阶段,我们使用约120M个图像文本对来对齐视觉和语言嵌入。对于第二阶段,我们使用20个多模态任务进行微调,其中包括图像或视频输入和NLP指令数据,以学习遵循指令。我们将所有多模态数据集转换为遵循指令的格式,其中包括手动编写的提示和更多的GPT4生成的提示,以保持所有训练数据的一致性。由此产生的模型在展示最准确的多模态理解能力的同时,还表现出了与现有开源模型相比最好的多模态生成能力。
2. Lynx
Lynx是一种GPT4风格的大型语言模型,可以将图像和视频作为输入。它建立在Vicuna之上,并通过高质量的图像文本和视觉语言任务对进行额外的可训练适配器训练。在本节中,我们将详细介绍我们的Lynx,包括问题公式化(2.1)、架构(2.2)、预训练(2.3)和指令微调(2.4)。
2.1 Formulations
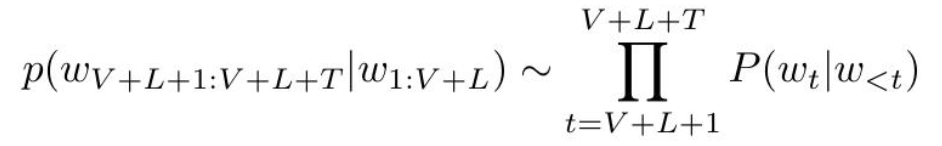
p\left(w_{V+L+1: V+L+T} \mid w_{1: V+L}\right) \sim \prod_{t=V+L+1}^{V+L+T} P\left(w_{t} \mid w_{<t}\right)在大型语言模型[1-13]中,网络通常会在大量文本语料库上进行训练,以学习标记之间的因果关系。同样,我们的模型也是在收集的视觉语言任务上进行训练,以学习下一个单词的分布。值得注意的是,与对比预训练[46,47]相比,使用下一个单词预测进行预训练需要具有流畅文本的数据,可以很好地表示预测单词和过去上下文之间的“自然”因果依赖关系[1]。我们将在第2.3和2.4节中详细介绍数据收集和选择的细节。
2.2 Details of Model Architecture
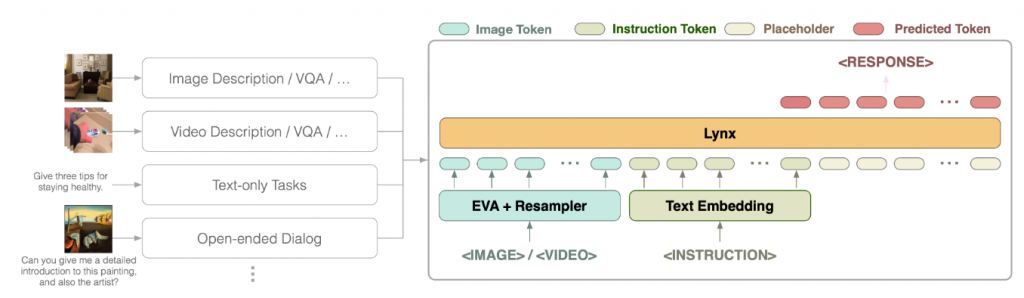
Overview 我们的模型同时将视觉和语言作为输入,根据输入指令生成文本响应。我们模型的总体结构如图1所示。具体来说,视觉输入首先由视觉编码器处理,得到一系列视觉标记wv。之后,wv与指令标记wl融合,用于多模态任务。在我们的模型中,我们直接将投影后的视觉标记和指令标记连接起来,作为LLMs的输入,然后可以自然地由仅解码器的LLMs处理。我们将这种结构称为“前缀微调”(PT),与像Flamingo [19]这样的交叉注意力模型形成对比。此外,我们发现通过在冻结的LLMs中的某些层后添加一个小的可训练适配器,可以进一步提高性能,同时训练成本较低。为了生成响应,从左到右的因果解码器自回归地预测下一个标记,将所有先前的标记作为输入,直到遇到<EOS>。
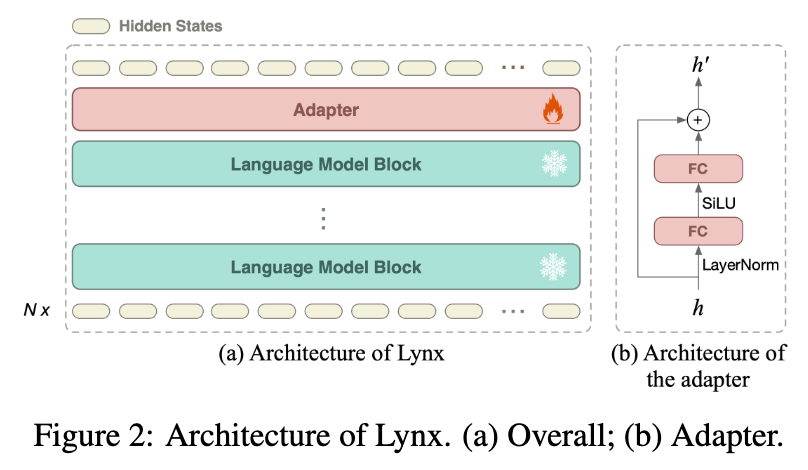
Adapter 可训练的适配器在每个M个块之后插入LLM中。在我们的实验中,M = 1。如图2(b)所示,适配器将每个标记线性投影到较低维度空间,然后重新投影回来。具体来说,在Lynx中,每个标记的隐藏状态为4096-d。适配器首先对隐藏状态施加层归一化[48]。然后使用线性层将每个标记状态的维数从4096降至2048,基于此,设置SiLU [49]作为非线性激活函数,与LLaMA [12]保持一致。最后,使用另一个线性层将2048-d隐藏状态重新映射回4096-d。
Vision Encoder 提取图像和视频帧的视觉特征,我们应用EVA-1B [50, 51]作为我们的视觉编码器φv(x)。它将图像映射为一系列视觉标记。下采样率为14,这意味着分辨率为H×W的图像将由H/14×W/14个标记序列表示。为了提高训练和推理的效率,我们采用了减少视觉输入维度的重采样器Φ机制[52, 19],将长视觉标记序列注入短且可学习的查询序列wqv中。其中x是输入图像,φv(x)是视觉编码器直接给出的原始标记,wv是由32个标记组成的压缩标记序列,不考虑视觉编码器给出的原始标记数量。wv = Φ(φv (x), wqv )
2.3 Pretraining
在预训练阶段,我们利用超过120M个图像文本对来训练新添加的层,以建立不同模态之间的连接。我们的预训练遵循典型的下一个单词预测训练,使用交叉熵损失。为了加速预训练,我们首先在224×224分辨率的图像上对模型进行预训练。然而,我们发现仅在低分辨率上进行预训练对于一些下游任务(如表格阅读和OCR)来说不足够。因此,在低分辨率图像上进行了100k步的预训练后,我们继续增加输入分辨率到420×420,并再进行10k步的训练。
在此阶段的训练数据主要包括BlipCapFilt 115M [39]、CC12M [53]、CC3M [54]和SBU [55]。此外,我们还在预训练期间添加了高质量的标记数据,这些数据也在指令微调阶段使用,如字幕、视觉问答和分类。所有预训练数据集的详细信息列在表9中。我们的模型在预训练阶段从所有这些数据集中训练了约14B tokens,指令微调阶段训练了约3B tokens。
2.4 Instruction Fintuning
为了用多样化的指令来优化我们的模型,我们基于公共数据集收集了一个指令微调多模态数据集。我们的数据集包括50多个仅文本、图像文本和视频文本任务,主要属于5个类别:仅文本指令跟随、图像/视频视觉问答、图像/视频字幕、分类以及基于图像的复杂推理和指令跟随的对话。我们还为所有这些任务提供了相应的指令(详见附录表9)。为此,我们为每个任务手动标记了至少3个不同的提示,然后调用GPT4基于以下“元提示”自动生成更多的提示,即用于为不同任务生成提示的提示。
Here are some instructions that define a visual-language task. Continue to write 15 instructions with
the same meaning: 1) PROMPT1; 2) PROMPT2; 3) PROMPT3;
此外,我们还收集了一些可用的公共(视觉)文本指令数据(也列在表9中),以进一步提高我们的模型遵循开放式指令的能力,包括FlanT5 [4]、Alpaca [14]、Mini-GPT4 [23]、LLAVA [56]和Baize [16]中使用的指令数据。我们遵循与预训练相同的因果预测损失,即交叉熵损失,以基于所有先前标记预测下一个单词。然而,我们观察到指令数据的不同权重组合对最终性能具有关键影响。根据经验,我们最终采用了表9中提出的权重策略。
3. Experiment
在本节中,我们旨在根据实证研究回答以下问题:
a)我们如何评估GPT4风格模型的性能?(第3.1节)
b)与现有模型相比,我们的Lynx有哪些优势?(第3.2节)
c)训练高性能的GPT4风格模型需要注意什么?(第3.3节)
d)Lynx在开放世界零-shot场景中的表现如何?(附录F节)
3.1 Evaluation Protocols 评估方式
GPT4风格的生成语言模型的评估具有挑战性,因为自然语言的质量本质上是主观的,并且高度依赖于具体情况。现有的模型,如PaLM-E [33]、PaLI [57]、BLIP2 [18]或InstructBLIP [24],转向在视觉语言基准上进行评估,如图像字幕[58]或视觉问答[42],即在单个下游任务上微调多模态LLM进行评估。然而,尽管可能实现更好的性能,但在这些基准上过度微调会损害大型语言模型的生成能力,这与使用大型语言模型的主要动机相冲突。此外,这些基准,特别是像TDIUC [59]这样的(半)自动生成的基准,总是包含高比例的简单或噪声的示例,使它们不太适合。相反,其他方法,如MiniGPT4 [23]或LLaVA [56],仅在一些具有挑战性但实用的场景中展示其性能,由于缺乏此类生成多模态语言模型的定量基准,因此没有定量结果。因此,在本节中,我们建议从以下两个方面评估GPT4风格的模型。
- 一个经过清理的视觉语言基准子集,应该具有挑战性并与生成模型兼容,通过prompt在GPT4上获得定量结果。
- 一个开放世界的具有挑战性但实用的测试集,用于评估GPT4风格模型在现实场景中的性能,由人类评估用户体验打分。
为此,我们手动收集了一个包含450个样本的Open-VQA测试集,其中包含有关对象、OCR、计数、推理、动作识别、时间顺序等各种问题的图像或视频输入,来自VQA 2.0 [42]、OCRVQA [60]、Place365 [61]、MSVD [62]、MSRVTT [63]和Something-Something-V2(SthV2)[64]。虽然Place365是一个分类任务,而SthV2是一个视频字幕任务,但我们编写了适当的提示,使它们都成为了VQA任务。此外,我们仔细检查数据,如果必要的话修改问题和正确答案,使它们可靠正确且具有足够的挑战性,成为GPT4风格模型的基准。随机抽样的示例如图3(a)所示。与传统的VQA基准不同,Open-VQA支持开放式答案。为了实现这一点,我们提示GPT4成为裁判,与人类相比,其一致性达到了95%以上2。本阶段用于GPT4的提示如下:
Given the question “QUESTION”, does the answer “PREDICTION” imply the answer “GROUND_TRUTH”? Answer with Yes or No.
此外,基于图像输入的通用语言生成对于多模态LLMs也非常重要。因此,我们还采用了mPLUG-owl提出的OwlEval测试集,其中包含82个问题,基于50张图像,其中21个来自MiniGPT-4 [23],13个来自MM-REACT [65],9个来自BLIP2 [18],3个来自GPT4 [45],以及4个由mPLUG-owl自己收集。测试集包括密集的图像字幕、对话写作、故事写作、诗歌写作、教学、编程等多样化和实用的案例。
我们在图3(b)中给出了一些例子。然而,OwlEval是与mPLUG-owl一起提出的。因此,直接将其用作基准可能对其他模型不公平。为了使比较公平,我们在将它们输入到模型之前,在OwlEval中的每个图像上填充8个像素,如图3(b)所示。我们招募人类注释者来评估性能。分数范围从1到5。如果两个模型被认为同样好或同样差,它们将获得相同的分数。对于每个数据,注释者将为每个模型分配一个分数。我们只允许最多有2个同样好或同样差的模型,并且对于每个注释者,整个集合的总平局数不应超过10个。在评估过程中,正确性具有最高优先级,然后应该是生成内容的丰富性。最后,我们还在新提出的MME基准测试[66]上与其他方法进行比较,该基准测试包括评估多模式大语言模型的感知和认知能力的14个不同子任务。
最后,我们还将我们的方法与其他方法在新提出的MME基准[66]上进行比较,该基准包括14个不同的子任务,评估多模式大型语言模型的感知和认知能力。

3.2 Quantitative Experiments
Open-VQA benchmark 我们首先在Open-VQA基准测试中评估了我们的模型以及几个现有的开源多模式LLM。结果如表8所示。我们可以得出结论,我们的模型在图像和视频理解任务中都取得了最佳性能。值得注意的是,InstructBLIP [24]在大多数情况下也取得了高性能,甚至在OCR、颜色识别和动作识别任务中比我们的模型表现更好。但我们发现它经常对问题仅输出一个单词(如图5和6),这让大多数用户都不太喜欢,如图4所示。我们还在第五图中展示了一些例子。附录中的第10和11图包括视频VQA示例等更多案例。我们可以看到,我们的模型在大多数情况下都能给出正确的答案以及支持答案的简洁原因,这使其更加用户友好。
OwlEval benchmark 我们评估了通用自然语言生成在OwlEval测试集上的表现。从图4中的人类评估结果可以看出,我们的模型在保持Open-VQA基准测试高性能的同时,具有最佳的语言生成性能。虽然BLIP2 [18]和InstructBLIP [24]在Open-VQA基准测试上取得了高性能,但由于它们的输出极短,即在大多数情况下,它们只输出一个单词或短语作为答案而没有任何解释,因此不受人类用户的青睐。相比之下,MiniGPT4 [23]和mPLUG-Owl [22]更注重语言生成能力而不是适应Open-VQA基准测试。因此,它们比BLIP模型更受欢迎,尽管它们可能会产生更多的事实错误。我们还在图6中展示了一些OwlEval的结果。
总的来说,我们观察到,如果一个模型在Open-VQA基准测试中的准确率较低,它往往会在文本生成过程中产生与给定图像不一致的事实错误。然而,表现更好的模型通常倾向于失去语言生成能力,例如生成短句子。我们将这个结论归因于视觉语言任务的欠训练或过度训练。具体而言,现有的视觉语言任务训练数据总是包括短输出。通过在这些数据上进行训练,模型可以学习将视觉和语言概念对齐,但会失去从大型语言模型继承的语言生成能力。从我们模型的高性能中,我们可以看到训练具有更好语言生成能力的高性能模型的一种可能的方法是仔细选择和清理数据,并设计适当的采样比例。然而,平衡语言生成和正确性的关键是一个包含清洁和丰富表达的高质量视觉语言数据集,这应该在我们未来的工作中探索。
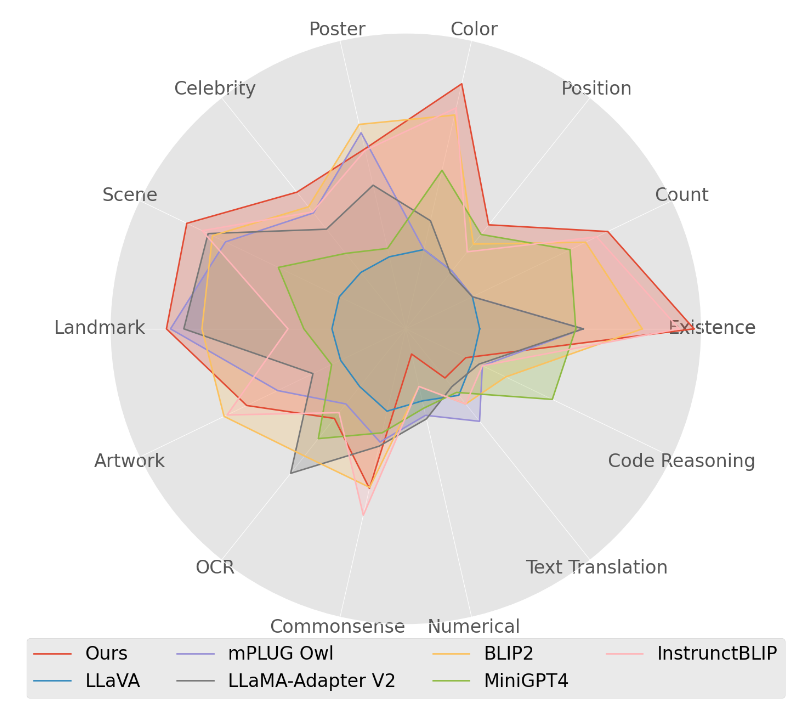
MME benchmark 我们还将Lynx与MME基准测试中现有的开源模型进行比较[66]。结果显示在图7和附录B中。我们可以看到,在14个子任务中,我们的模型在7个子任务中是最先进的模型,特别是在包括颜色、名人、场景、地标、位置、计数和存在等感知任务中。然而,从图中我们也可以看到,我们的模型在包括代码推理、文本翻译和数字等认知任务上似乎表现不佳。值得注意的是,MME中的认知基准测试,包括代码推理、文本翻译和数字,只包含20个示例,这可能导致不同检查点的评估存在高方差。
3.3 Ablation Study
我们进行了深入的消融研究,以调查不同组件或训练配方对多模态理解和语言生成性能的影响。在本节中,我们遵循第3.1节提出的相同评估方法。
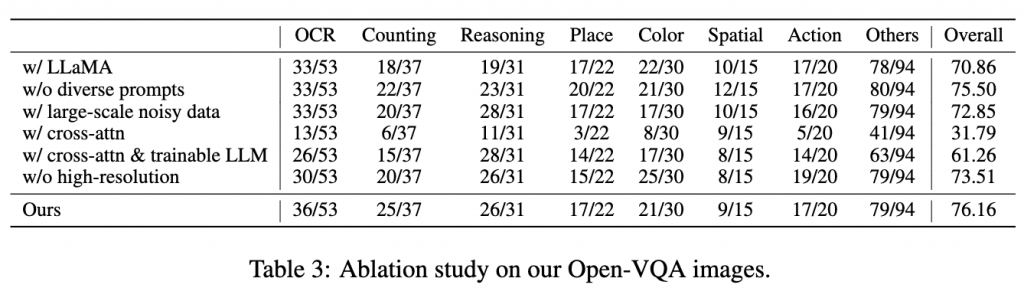
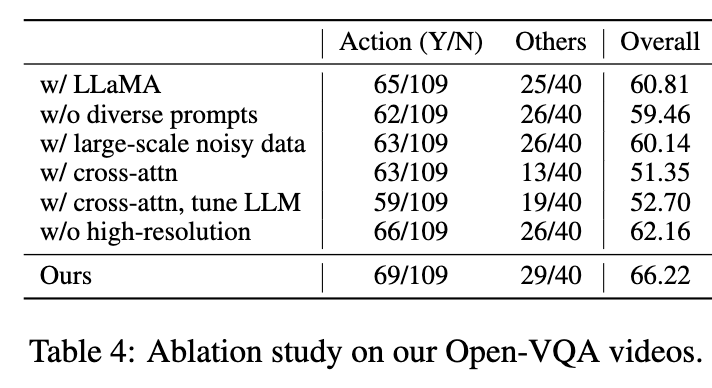
LLaMA vs. Vicuna 如表3所示,我们的实验表明,在正确性方面,指令微调的骨干网络(例如Vicuna)在我们的Open-VQA基准测试(如LLaVA)上表现略好,如表3和4所示,但在OwlEval基准测试(图4)上略逊色。然而,基于Vicuna的模型确实更好地遵循指令。例如,给定指令“给出简短的答案”,平均答案长度为15.81,而LLaMA-based模型为20.15。也可以参考图9(a)以了解它们在遵循指令方面的比较示例。
Impact of Diversified Prompts 多样化提示的影响已被证明对于训练LLMs以正确遵循指令非常重要[4,7]。因此,我们使用由用户和GPT4编写的多样化提示来检验我们的模型。表3和4中的结果表明,我们的提示有助于平衡不同的能力。此外,我们还发现,通过使用多样化提示,我们的模型可以比没有这些提示训练的模型更好地遵循开放式指令(表10)。这一观察结果与仅文本模型相符。图8(b)中的人类评估结果也与我们的观察结果相符。多样化任务和提示将有助于提高模型对新任务和指令的泛化能力。
Impact of Training Data 我们通过使用大规模但嘈杂的图像文本对(COYO700M [40]和DataComp1B [41])来训练我们的模型,研究数据数量和质量的影响。在我们的实验中,我们发现预训练和微调中的训练数据在很大程度上影响了模型性能。与传统的视觉语言预训练[47]不同,我们发现多模态LLMs不受益于大规模但嘈杂的图像文本对,因为这些数据集中的许多文本不是流畅或自然的语言表达。对于我们模型中的生成式预训练,它们在很大程度上破坏了语言生成能力,如图9(b)所示。因此,与仅在更小但更干净的数据集上训练相比,使用这样的大规模数据集进行预训练并没有取得更好的结果,如图8(c)所示,由人类用户评估。
Prefix-Tuning vs. Cross-Attn 我们遵循Flamingo [19],具体来说是Open-Flamingo [67],来实现交叉注意力方法。按照其原始设置,我们仅使用多模态指令数据进行预训练。在微调阶段,我们尝试了两种变体,即使用或不使用可训练的LLM,即使用或不使用文本指令数据。如表3和4所示,它们都比我们的前缀调整与适配器表现更差。尽管模型可以生成流畅和相关的响应,但它们的输出通常不能正确回答问题。我们还通过人类注释者验证了我们的结论,如图8(d)所示。结果表明,人类用户对交叉注意力模型的偏好较低。总体而言,交叉注意力模型可能需要更多的超参数搜索才能实现更好的性能,我们将其留给进一步的工作。
Impact of Larger Image Resolution 我们在第一阶段仅进行了10K步训练就增加了图像分辨率。之后,我们冻结了视觉编码器,因此增加图像分辨率的成本是可以承受的。为了严谨起见,我们还进行了一项实验,以验证图像分辨率对模型性能的影响。表3和4中的实验结果表明,训练420×420分辨率的模型比仅训练224×224分辨率的模型表现更好。
6 Conclusion
在本文中,我们介绍了Lynx,这是一个多模态的GPT4风格的大型语言模型,可以接受图像/视频作为输入,并用开放式自然语言进行回应。通过广泛的实证研究,我们表明我们的模型在多模态理解和语言生成方面优于其他现有的开源模型。我们还探讨了影响多模态大型语言模型性能的不同因素,并得出结论:1)对于网络结构,前缀调整比交叉注意力更好地融合不同的模态;2)指令跟随与用于训练的任务和提示数量密切相关;3)生成预训练对训练数据的质量更为敏感,而不是先前的对比训练等预训练方法;4)平衡正确性和语言生成对于多模态大型语言模型非常重要。
未来的工作,有望将模型扩展到更大的规模(例如30B和65B LLaMA [12]),以及更大更多样化的教学任务集。此外,还需要一个大规模且高质量的多模态数据集来训练这样的模型。因此,收集这样的数据集是值得努力的,这将对这个领域做出巨大的贡献。多语言能力和安全性对于实际应用也无疑是至关重要的。
![[翻译] UNITER:通用图文表示学习](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)