DPO 的核心是跳过显式奖励模型训练和强化学习采样,直接用 “输入 x + 偏好回复 yₙ+ 非偏好回复 yₗ” 的三元组数据,通过简单的分类损失函数优化模型,让模型对齐人类偏好,全程无需模型凭空生成新回复。
一、准备
1. 偏好数据集构建
核心数据格式:每个样本是三元组 (x, yₙ, yₗ)
数据来源:人类标注者对模型初始生成的回复进行 pairwise 偏好判断(二选一),无需标注绝对分数。
x:用户输入提示(如 “我弄坏了朋友的东西,该怎么说?”)yₙ(chosen):人类偏好的优质回复(如 “主动道歉,问问能不能赔偿”)yₗ(rejected):人类不偏好的劣质回复(如 “假装不知道,别理他”)
2. 参考模型(π_ref)初始化
参考模型是 “能力基准”,用于限制训练中模型的偏离程度,避免能力退化:
- 优先选择:已训练好的监督微调模型(SFT 模型),即通过高质量单轮回复微调后的基础模型;
- 备选方案:若无 SFT 模型,可在偏好数据集的
(x, yₙ)对上做简单监督微调,得到仅学习优质回复的模型作为π_ref。参考模型的参数在 DPO 训练中固定不变,仅用于计算约束项。
3. 目标模型(π_θ)初始化
目标模型是待优化的模型,初始参数直接复用参考模型 π_ref 的参数,避免从零训练导致的效率低下和稳定性问题。
二、训练
第一步:数据预处理 —— 拼接序列并转 token
将三元组数据转换为模型可处理的输入格式:
- 对每个样本,分别拼接两个完整序列:
- 优质序列:
x + yₙ(如 “我弄坏了朋友的东西,该怎么说?+ 主动道歉,问问能不能赔偿”) - 劣质序列:
x + yₗ(如 “我弄坏了朋友的东西,该怎么说?+ 假装不知道,别理他”)
- 优质序列:
- 通过模型的 tokenizer 将两个序列转为 token ID(
chosen_input_ids、rejected_input_ids),并生成对应的注意力掩码(attention_mask),标记有效 token 位置。
第二步:计算对数概率 —— 评估现成回复的 “得分”
DPO 无需生成新回复,仅计算模型对已有 yₙ 和 yₗ 的生成概率(对数形式,记为 logps),步骤如下:
- 分别将
chosen_input_ids和rejected_input_ids输入目标模型π_θ,得到模型输出的 logits(未归一化的预测分数); - 提取回复部分(
yₙ或yₗ对应的 token 位置,跳过输入x的 token)的 logits,通过log_softmax转换为对数概率; - 按
yₙ/yₗ的真实 token 序列,提取每个位置的对数概率并求和,得到整个回复的对数概率:- 优质回复对数概率:
chosen_logps = sum(log P_θ(yₙ_token | x, yₙ_prev_tokens)) - 劣质回复对数概率:
rejected_logps = sum(log P_θ(yₗ_token | x, yₗ_prev_tokens))
- 优质回复对数概率:
同时,用参考模型 π_ref 对相同的两个序列做同样计算,得到 ref_chosen_logps(π_ref 对 yₙ 的对数概率)和 ref_rejected_logps(π_ref 对 yₗ 的对数概率)。
第三步:计算 DPO 损失函数 —— 约束偏好与偏离度
DPO 的损失函数核心是 “抬高 yₙ 概率、压低 yₗ 概率,同时控制与参考模型的偏离”,公式如下:
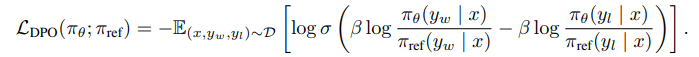
- 符号说明:
y_w=yₙ(偏好回复),y_l=yₗ(非偏好回复);σ(·)是 Sigmoid 函数,将输入压缩到 [0,1] 区间,确保损失值可导且稳定;β是超参数(通常取 0.1~0.5),控制与参考模型的 KL 散度约束强度:β越大,模型越贴近π_ref,越保守;β越小,模型越倾向于优化偏好,可能偏离基础能力。
- 损失函数逻辑:
- 当
π_θ对yₙ的相对概率(相对于π_ref)高于yₗ时,σ(·)输出接近 1,log(σ(·))接近 0,损失小; - 当
π_θ认为yₗ更好(相对概率更高)时,σ(·)输出接近 0,log(σ(·))接近负无穷,损失大,强制模型反向调整。
- 当
第四步:梯度下降优化 —— 迭代更新模型参数
- 对批次内所有样本的损失值求平均,得到总损失;
- 通过反向传播计算总损失对目标模型
π_θ参数的梯度; - 用优化器(如 AdamW、RMSprop)更新
π_θ的参数,降低损失; - 重复 “第二步~第四步”,迭代多轮(通常远少于 RLHF,10~50 轮即可收敛),直到损失稳定、模型对
yₙ的偏好概率显著高于yₗ。
![[翻译]See Better Before Looking Closer](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)