Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
背景
VLP(Vision and Language Pre-training)架构有如下限制:
- 图像特征和文本特征分布在各自领域,使得多模态模型很难学到它们的相互影响
- 物体检测需要昂贵的标注成本和计算成本,因为在预训练时需要bbox标注,在推理时需要高分辨率图像
- 当前广泛使用的image-text数据集收集自网络,因此存在很多噪声,现有预训练目标MLM可能会过拟合噪声文本,降低模型泛化性能
本文提出
- 用来对其图像和文本表达的对比损失
- 用来在噪声数据中提升效果的动量蒸馏
- 用互信息最大化来解释ALBEF
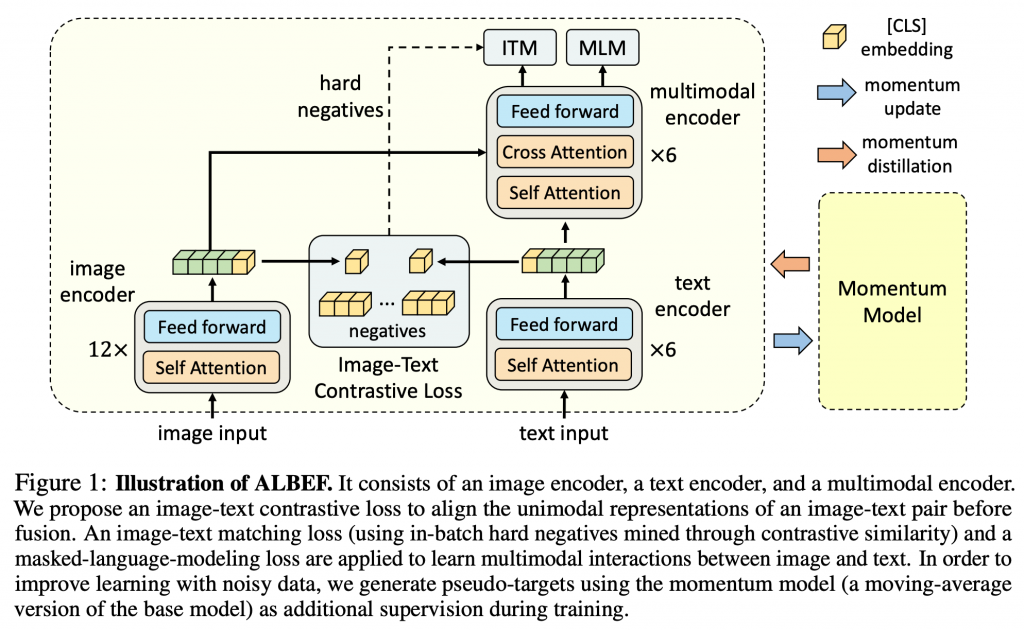
模型结构
使用12层ViT-B/16作为图像encoder将图像映射为{vcls, v1, …, vN},使用前6层BERTbase作为文本encoder,使用后6层BERTbase作为多模态encoder,文本编码器将输入文本映射为{wcls, w1, …, wN}
图片-文本对比学习(ITC)
在图像和文本进行跨模态注意力之前使用image-text对比损失对齐图像和文本表达
- 对齐文本和图像特征,使多模态encoder更容易训练
- 改进单模态encoder使其更好的理解文本和图像的语意含义
- 网络学到了图像和文本共同的低维嵌入空间,使图像-文本匹配目标可以通过对比难负例挖掘找到更多信息样本
具体实现:
- 将图像特征vcls 和文本特征wcls 分别经过gv和gw的线性变换和归一化映射到256d空间,I=gv(vcls),T=gw(wcls)
- 通过向量点乘,计算图像特征和文本特征相似度s = I⊤T
- 使用动量单模态encoder模型得到图像特征vcls‘ 和文本特征wcls‘ ,同上映射为I‘=gv‘(vcls‘),T‘=gw‘(wcls’)
- 借鉴MoCo思想,维持两个队列存储最近的M个图像表达MI={I0,I1, …, Im}和文本表达MT={T0, T1, …, Tm}
- 计算I与MT中各Tm的相似度,得到pmi2t,其groundtruth为one-hot编码,记为yi2t,计算交叉熵损失Li2t
- 计算T与MI中各Im的相似度,得到pmt2i,其groundtruth为one-hot编码,记为yt2i,计算交叉熵损失Lt2i
- Lossitc = 0.5*(Li2t+Lt2i)
- 动量蒸馏方法优化方式:使用I‘与MT计算的相似度代替yi2t,使用T’与MI计算的相似度代替yt2i
理论解释:互信息最大化视角
待补充
掩码语言任务
略,Lossmlm
图片-文本匹配任务
略,Lossitm
动量蒸馏方法(MoD)
预训练的图像-文字对大部分是从网上收集的,导致存在噪声,正例对通常是弱相关的——文本中的词汇和图像没有关系,或是图像中的实例在文本中没有描述。对于ITC任务图像的负例文本可能也匹配图像内容,对于MLM任务可能存在另一个不同于标注的单词但完美表述了图像,但ITC和MLM的one-hot标签会使得无论其是否正确都需预测为负例。
因此我们提出用动量模型产生的伪目标进行学习,动量模型是由指数移动平均版本的单模态模型和多模态编码器组成的不断学习的教师模型。在训练时,我们训练基础模型使其与动量模型的输出相匹配。
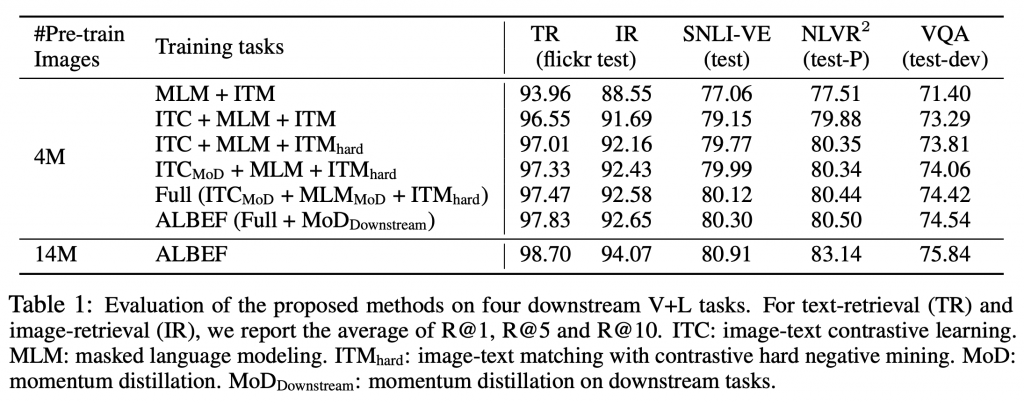
结论
本文提出了一种新的视觉语言表示学习框架ALBEF。ALBEF首先将单模态图像表示和文本表示对齐,然后将它们与多模态编码器融合。我们从理论和实验上验证了所提出的图像-文本对比学习和动量蒸馏的有效性。与现有方法相比,ALBEF在多个下游V+L任务上提供了更好的性能和更快的推理速度。
虽然我们的论文在视觉语言表示学习方面显示了有希望的结果,但在实际部署之前,有必要对数据和模型进行额外的分析,因为网络数据可能包含意外的私人信息、不合适的图像或有害的文本,只优化准确性可能会产生不利的社会影响。
![[略读]ObjectBox](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)