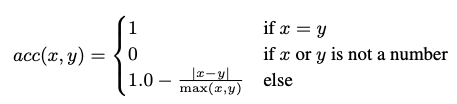文献
TAPAS:Weakly Supervised Table Parsing via Pre-training
Abatract
通过表格回答自然语言问题通常被视为语义解析任务。为了减轻完整逻辑格式的数据收集成本,一种常用的方法是使用侧重于由表达结果(denotation)而不是逻辑格式的弱监督。但从弱监督中训练语义解析器比较困难,并且生成的逻辑形式仅被用作检索表达结果之前的中间步骤。在本文中,我们提出了TAPAS,一种在不生成逻辑形式的情况下通过表格回答问题的方法。TAPAS从弱监督中训练,通过选择单元格并选择性地将相应的聚集运算符应用于所选单元格来预测表达结果。TAPAS扩展了BERT的体系结构,将表格作为输入进行编码,通过对从维基百科抓取的文本段和表进行有效的联合预训练进行初始化,进行端到端的训练。我们用三个不同的语义解析数据集进行实验,发现TAPAS比语义解析模型有竞争力甚至更优,因为它将SQA上SOTA的准确率从55.1提高到67.2,在WIKISQL和WIKITQ上的表现与SOTA水平相当,但模型架构更简单。我们还发现,从WIKISQL到WIKITQ的迁移学习在我们的设置中非常容易,可以产生48.7的准确率,比SOTA高出4.2个百分点。
Introduction
半结构化表格的问答任务通常被视为语义解析任务,其中问题被翻译成逻辑形式,可以在表格上执行以检索正确的表达结果。语义解析器依赖于将自然语言问题与逻辑形式配对的监督训练数据,但是标注这些数据非常昂贵。
近年来,有许多旨在减轻语义解析的数据采集负担的尝试,包括paraphrasing, human in the loop, training on examples from other domains. 一种重要的数据采集方法关注弱监督,即训练示例由问题及其表达结果组成,而不是完整的逻辑形式。尽管这种方式很引人注目,但由于大量虚假的逻辑形式和稀疏奖励,从这个输入训练语义解析器通常很困难。
此外,语义解析应用程序只利用生成的逻辑形式作为检索答案的中间步骤。然而,生成逻辑形式会带来一些困难,如保持具有足够表现力的逻辑形式、遵守解码约束(例如良好的形式)和标签偏差问题。
在本文中,我们提出了TAPAS(用于表解析器),这是一个弱监督的问答模型,它在不生成逻辑形式的情况下对表进行推理。TAPAS是通过选择表单元格的子集以及在它们之上执行某些聚合操作来预测的最小程序。因此,TAPAS可以从自然语言中学习操作,而不需要在某种格式中指定它们。这是通过扩展BERT的体系结构(Devlin等人,2019年)来实现的,在该体系结构中增加爱了捕获表格结构的embedding,以及用于选择单元格和预测相应聚合运算符的两个分类层。
重要的是,我们为TAPAS引入了一种预训练方法,这对它在最终任务中的成功至关重要。我们将BERT的掩蔽语言模型目标扩展到结构化数据,使用从维基百科抓取的上百万表格和相关文本片段进行模型预训练。在预训练期间,模型从文本段和表格本身mask一些token,目标是基于文本和表格上下文预测原始mask token。
最后,我们提出了一个端到端的可微训练配方,允许TAPAS从弱监督中训练。对于只涉及选择表中单元格子集的示例,我们直接训练模型选择黄金子集。对于涉及聚集的示例,无法从表达结果中获取相关的单元格和相应的聚集操作。在这种情况下,我们在给定的当前模型上计算所有聚集算子的 expected soft scalar outcome,并用针对gold denotation的回归损失来训练模型。
在不生成逻辑形式的情况下,与之前算法进行表格推理比较,TAPAS达到了最高的准确率,并有几个优势:它的架构更简单,因为它包括一个没有自回归解码的单一编码器,更适合预训练,能处理更多的问题类型,如涉及聚合的问题,并能直接处理对话场景。
我们发现,在三个不同的语义解析数据集上,与其他语义解析和问答模型相比,TAPAS的性能更好或相当。在对话SQA上,TAPAS将最先进的准确率从55.1提高到67.2,并在WIKISQL和WIKITQ上实现了同等的性能。迁移学习在TAPAS中很简单,从WIKISQL到WIKITQ的准确率达到48.7,比SOTA高4.2分。代码和预训练模型开源。
TAPAS Model
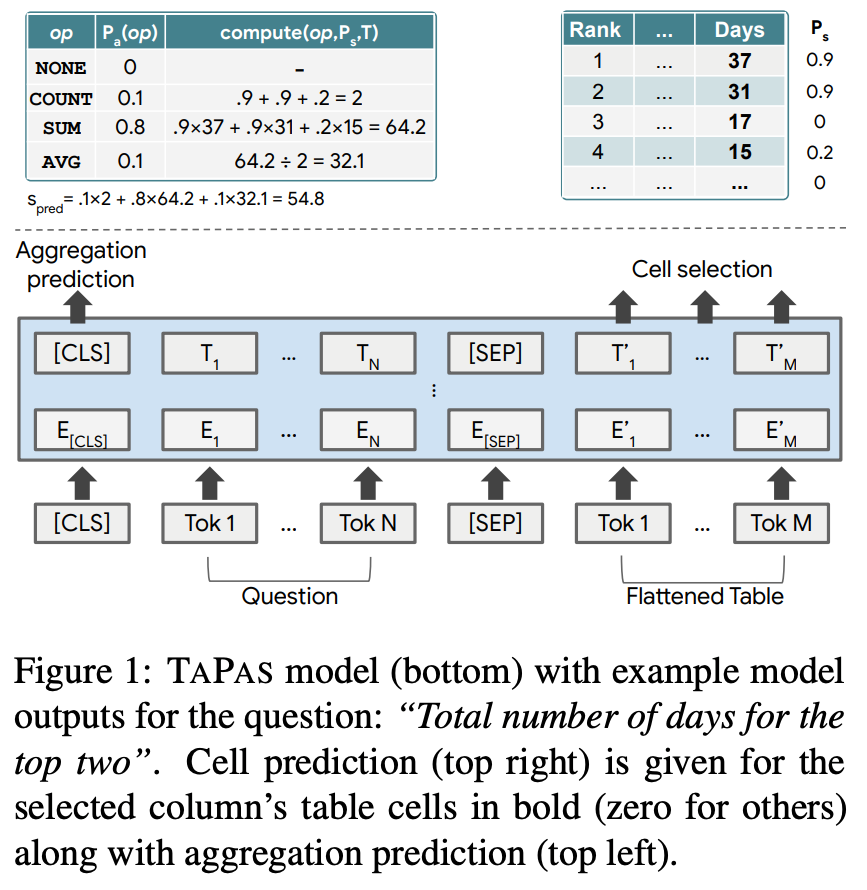
我们的模型架构基于BERT的编码器(如图1),带有用于编码表格结构的额外位置嵌入(如图2所示)。我们将表格展平为words序列,将words拆分为word的token组成tokens,并将问题tokens加在表格tokens之前。我们另外添加了两个分类层,用于选择单元格和选择对单元格进行操作的聚合运算符。

Additional embeddings 我们在问题和表之间添加分隔token,并在送入模型前与表位置感知token组合,这与Hwang et al. (2019) 不同。我们使用不同类型的位置嵌入:
- Position ID 表格展平后的顺序标记
- Segment ID 有两个值,0表示问题,1表示表头和单元格
- Column / Row ID 在问题中为0,在表格中是表示token所在行、列
- Rank ID 如果列值可以被解析为浮点数或日期,我们会对它们进行相应的排序,并根据它们的数字排名分配嵌入(0代表不可比,1代表最小的项目,i+1代表排名为i的项目)。这可以在涉及最高级的问题时帮助模型,因为单词块不能表示数字排序
- Previous Answer 给定当前问题可能涉及前一个问题或其答案的对话设置(如图3中的问题5),我们添加了一个特殊的嵌入,标记单元格令牌是否是前一个问题的答案(如果token内容是答案,则为1,否则为0)。
Cell selection 分类层选择表格子集,根据所选聚类操作符,这些单元格可以是最终答案,也可以是用于计算最终答案的输入。单元格被建模为独立的伯努利变量。首先,我们在token的最终隐向量上加线性层计算logit,然后将一个单元格中的所有logit求平均作为单元格的logit。该层的输出p(c)s是选择单元格c的概率。另外我们发现增加归纳偏置在单列中选择单元格式有效果的,我们通过引入一个分类变量来选择正确的列来实现这一点。列中所有单元格的embedding 平均后通过新线性层来计算列的logit。我们添加一个额外的列logit,对应于不选择列或单元格,我们将其视为没有单元格的额外列。该层的输出p(co)coll是使用softmax在列logits上计算选择列co的概率,我们将选定列之外的单元格概率p(c)s设置为0。
Aggregation operator prediction 语义解析任务需要对表进行离散推理,例如求和数字或计数单元格。为了在不产生逻辑形式的情况下处理这些情况,TAPAS输出表单元格的子集以及可选的聚合运算符。聚合运算符描述了应用于所选单元格的操作,例如SUM、COUNT、AVERAGE或NONE。运算符由第一个token(特殊的[cls] token)的最终隐向量,经过线性层+softmax后选择,记为pa(op),其中op是聚合运算符。
Inference
我们预测最有可能的聚合运算符以及使用单元格选择层选择最有可能的单元格子集。为了预测离散单元格选择,我们选择其概率大于0.5的所有表单元格。然后对表执行这些预测,通过在选定单元格上应用预测的聚合运算符来检索答案。
Pre-training
随着最近针对自然语言理解任务的文本数据预训练模型的成功,我们希望将这一过程扩展到结构化数据,作为我们表解析任务的初始化。为此,我们在维基百科的大量表上预训练TAPAS。这允许模型学习文本和表之间以及列的单元格和它们的标题之间的许多有趣的相关性。
我们通过从维基百科中提取文本-表格对来创建预训练输入。我们提取了6.2M表格:Infobox类型的3.3M,WikiTable类型的2.9M。我们限制表格最多有500个单元格。我们实验中的所有任务数据集都是只带有列名作为标题行的水平表。因此,我们在维基表中只使用<th>标签来识别和提取标题。此外,我们将Infobox转置为具有单个标题和单个数据行的表。从Infobox创建的表可以说不是非常典型,但我们发现它们提高最终任务的性能。
作为最终任务中问题的替代,我们提取表格标题、文章标题、文章描述、片段标题和表格所在片段的文本作为相关文本片段。这样我们提取21.3M片段。
我们将提取的文本表对转换为预训练示例,如下所示:遵循Devlin et al. (2019),我们使用掩蔽语言模型预训练目标。我们还尝试添加第二个目标,即预测表是属于文本还是随机表,但发现这不能提高最终任务的性能。
为了提高预训练的效率,我们将单词片段序列长度限制在一定的范围内(例如,我们在最终实验中使用128个)。也就是说,标记化文本和表格单元格的组合长度必须适配这个范围。为了实现这一点,我们从相关文本中随机选择8到16个单词片段。为了适合表格,我们从只添加每个列名和单元格的第一个单词开始,然后我们依次添加单词,直到我们达到单词片上限。对于每个表,我们以这种方式生成10个不同的片段。
我们遵循BERT引入的掩蔽过程。我们对文本使用整个单词掩蔽,我们发现对表格应用整个单元格掩蔽(如果单元格的任何部分被掩蔽,则掩蔽单元格的所有单词片段)也是有益的。
我们还尝试了数据增强,这与预训练有着相似的目标。我们通过语法在真实表格上生成合成的问题和结果表达对,并将这种增强应用到最终任务的训练数据中。由于这并没有显著提高最终任务的性能,我们忽略了这些结果。
Fine-tuning
在如下所示的弱监督设置中,我们正式定义了表格解析。给定含有N个例子的训练集{(xi, Ti, yi)}N i=1 ,x是语句,T是表格,y是相应结果表达,我们的目标是训练一个将语句x映射到程序z的模型,这样z在表格T上执行时,会产生正确的结果表达y。程序z包括表格单元格子集和可选的聚合运算符。
作为第5.1节中描述的预处理步骤,我们将每个示例的结果表达y转换为元组(C, s),C是单元格坐标,s是仅当y是单个标量时才填充的标量。然后,我们根据(C, s)的内容指导训练。对于单元格选择示例(即s为空),我们训练模型选择C中的单元格。对于标量答案示例(即C为空),我们训练模型来预测数量指向s的表单元格聚合运算。

Cell selection
用图3中的问题1举例,在这种情况下,y映射到表单元格坐标C的子集。对于这种类型的示例,我们使用分层模型,首先选择一列,然后只选择该列中的单元格。我们直接训练模型选择C中单元格数量最多的列col。对于我们的数据集,单元格C包含在单个列中,因此对模型的这种限制提供了有用的归纳偏差。如果C是空的,我们选择额外的空列对应需选择空单元格。然后训练模型选择单元格C∩col,而不选择(T\C)∩ col。损失由三个部分组成:

Scalar answer
用图3中的问题2举例,在这种情况下,y是一个没有出现在表中的单个标量,即C=∅。这通常对应于涉及一个或多个表单元格的聚合的示例。在这项工作中,我们处理对应于SQL的聚合运算符,即COUNT、AVERAGE和SUM,但是我们的模型并不局限于这些。
对于这些示例,应该选择的表单元格和聚合运算符类型是未知的,因为这些不能直接从标量答案s中获取。为了训练这种给定监督形式的模型,可以离线搜索或在线搜索,寻找表单元格和聚合执行到s的程序。在我们的表解析设置中,执行黄金标量答案的虚假程序的数量可以随着表单元格的数量快速增长(例如,当s=5时,任何五个单元格上的COUNT都可能是正确的)。由于这种方法学习很容易失败,我们没有使用它。
相反,我们使用不需要搜索正确程序的训练方法。我们的方法使用端到端的可微训练,在思路上类似于Neelakantan et al. (2015)。我们实现了一个完全可微的层,它潜伏地学习聚合预测层pa(·)的权重,而不需要对聚合类型进行明确的监督。
具体来说,我们发现执行每个聚合运算符的结果都是标量。然后,我们为每个运算符实现软可微估计,给定令牌选择概率和表值:计算(op,ps,T)。给定所有聚合运算符的结果,我们然后根据当前模型计算预期结果:

对于一些例子,Jscalar可能非常大,这会导致模型更新不稳定,我们引入了cutoff超参数。对于Jscalar>cutoff的训练情况,设置J=0来完全忽略这条数据,因为我们注意到这种行为与异常值相关。此外,由于训练期间完成的计算是连续的,而推断期间完成的计算是离散的,我们进一步添加了temperature来缩放token logits,使得ps输出的值更接近0或1。
Ambiguous answer
这种问题需要用聚合运算解答(如图3中的问题3),同时标量答案s也出现在表格中(图3中的问题4),是Ambiguous的。因此在这种情况下,我们动态地让模型根据其当前策略选择监督(cell selection or scalar answer)。具体地说,如果pa(op0)≥S,我们将监督设置为cell selection,其中0<S<1是阈值超参数,否则是scalar answer。这遵循hard EM,至于虚假程序我们根据当前模型选择最可能的程序。
Experiments
Datasets
WIKITQ 这个数据集由维基百科表格上的复杂问题组成。给众包标注员(Crowd workers)一张表格,让他们提出一系列复杂的问题,包括比较、最高级、聚合或算术运算。然后这些问题被其他众包标注员验证。
SQA 这个数据集是通过让众包标注员分解来自WIKITQ的高度合成问题子集来构建的,其中每个分解后的问题都可以由一个或多个表单元格来回答。最终由6066个问题序列组成(平均每个序列2.9个问题)。
WIKISQL 这个数据集专注于将文本翻译成SQL。它是通过让众包标注员用自然语言构建一个基于模板的问题来构造的。另外两个众包标注员被要求验证所提议的解释的质量。
当我们的模型预测单元格选择或标量答案时,我们将每个数据集的结果表达转换为(问题、单元格坐标、标量答案)的三元组。SQA已经提供了这些信息(每个问题的黄金单元格)。对于WIKISQL和WIKITQ,我们只使用结果表达。因此,我们通过将结果表达与表内容相匹配来导出单元格坐标。如果结果表达包含可以解释为浮点数的单个元素,我们将填充标量答案信息,否则我们将其值设置为NaN。如果没有标量答案,并且在表中找不到结果表达,或者如果某些结果表达与多个单元格匹配,我们将删除示例。
Experimental Setup
我们将标准的BERT tokenizer应用于问题、表格单元格和标题,使用相同的32k词汇表。数字和日期的解析方式与Neural Programmer相似。
我们从BERT-Large开始预训练(有关超参数,请参见附录B)。我们发现从预训练BERT模型开始预训练是有益的(同时随机初始化我们的附加嵌入),因为这增强了保留数据的收敛。我们在32个 Cloud TPU v3核的设置上运行预训练和微调,最大序列长度为512。在这个设置中,WIKISQL和WIKITQ的预训练需要大约3天,微调大约10个小时,SQA需要20个小时(批处理大小来自表12)。我们模型的资源需求基本上与BERT-Large相同。
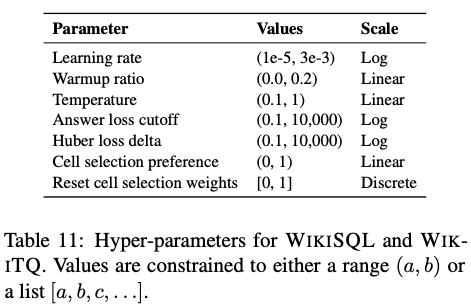
对于微调,我们使用类似于Google Vizier的黑盒贝叶斯优化器为WIKISQL和WIKITQ选择超参数。对于SQA,我们使用网格搜索。
Result
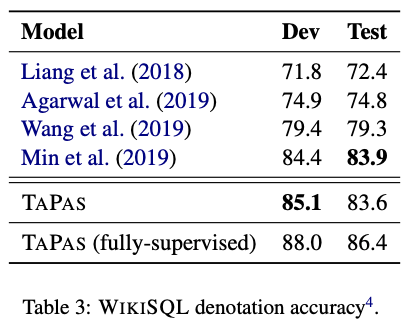
所有结果都为从弱监督中预训练后模型的表达精度。我们报告了5次独立运行的中位数,因为基于BERT的模型可能会退化。我们分别在表3和表4中展示了我们对WIKISQL和WIKITQ的结果。表3显示,预训练后的TAPAS在WIKISQL接近SOTA(83.6 vs 83.9)。如果给定聚合运算符和选定的单元格作为监督(从参考SQL提取),这对TAPAS来说是完全监督,则模型达到了86.4。与完全SQL查询不同,这种监督可以由非专家注释。

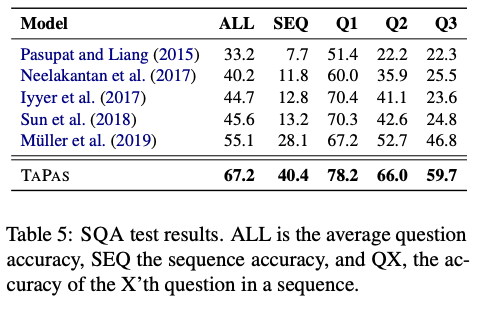
对于WIKITQ,仅从原始训练数据训练的模型达到42.6,超过了类似的方法。当我们在WIKISQL或SQA(这在我们的设置中是直接的,因为我们不依赖逻辑格式)上预训练模型时,TAPAS分别达到48.7和48.8。
对于SQA,表5显示了TAPAS对所有指标的实质性改进:将所有指标提高至少11点,序列准确度从28.1提高到40.4,平均问题准确度从55.1提高到67.2。
消融实验 Model ablations
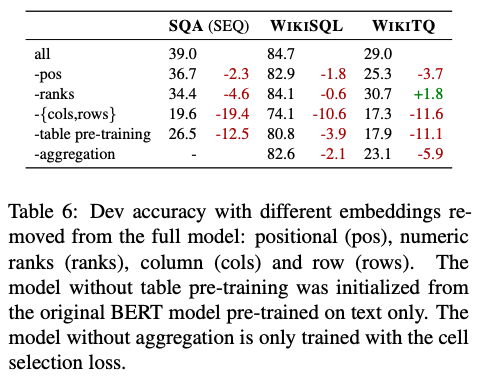
表6显示了对我们不同embedding的消融研究。为此,我们对具有不同特征的模型进行了预训练和微调。由于预训练代价昂贵,我们将其限制在20万步。对于所有数据集,我们看到表以及列和行嵌入的预训练是最重要的,位置和等级嵌入也在提高质量但程度较低。
我们还发现,当从TAPAS中删除标量答案和聚合损失(即设置JSA=0)时,两个数据集的准确性都会下降。对于WIKITQ,我们观察到删除聚合时性能从29.0大幅下降到23.1。对于WIKISQL,性能从84.7下降到82.6。对于WIKISQL,相对较小的下降可以解释为大多数示例不需要聚合来回答。
原则上,开发集中17%的例子有聚合操作(SUM、AVERAGE或COUNT),但是我们发现,对于98%以上的所有类型示例,聚合只应用于一个或没有单元格。在SUM和AVERAGE的情况下,这意味着大多数示例可以通过从表中选择一个或没有单元格来回答。对于COUNT,没有聚合运算符的模型实现了28.2的精度(通过从表中选择0或1),而对于具有聚合的模型精度为66.5。请注意,0和1通常在一个特殊的索引列中找到。WIKISQL的这些属性使得模型很难决定是否应用聚合。另一方面,对于WIKITQ,当删除聚合时,我们观察到性能从29.0大幅下降到23.1。
WIKITQ定向分析
我们手动分析了TAPAS在WIKITQ上做出的200个开发集预测。对于通过聚合完成的正确预测,我们检查所选的单元格看看它们是否匹配真值。我们发现96%的正确聚合预测在所选单元格方面也是正确的。我们进一步发现14%的正确聚合预测只有一个单元格,并且有可能通过单元格选择来实现,而不是聚合。
我们还进行了错误分析,并确定了以下独特的显著现象:
- 12%含糊不清(“Name at least two labels that released the group’s albums.”),有错误的标签或丢失的信息;
- 10%的情况需要复杂的时间比较,这种问题也不能通过逻辑格式解析,如SQL(“what country had the most cities founded in the 1830’s?”);
- 在16%的情况下,黄金表达中含有表中没有出现过的文本值,因此如果不对单元格内值执行字符串操作,就无法预测;
- 在10%的情况下,表太大,无法容纳512个token;
- 在13%的情况下,TAPAS选择没有单元格,建议对这种情况增加处罚;
- 在2%的情况下,答案是标量之间的差异,因此它超出了模型的能力(“how long did anne churchill/spencer live?”);
- 其他37%的情况下无法归类为特定现象
Pre-training Analysis
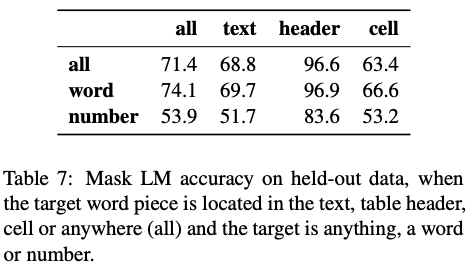
为了了解TAPAS在预训练中学到了什么,我们分析了它在10,000个保留数据(hold-out data)中的表现。我们拆分数据,使得保留数据中的表格不会出现在训练数据中。表7显示了不同类型和不同位置的掩蔽单词片段的准确性。我们发现跨位置的平均准确性相对较高(71.4)。预测表头的token是最容易的(96.6),可能是因为许多维基百科文章使用相同类型表格的实例。预测单元格中的单词片段(63.4)比预测文本中的片段(68.8)要难一点。在比较预测单词(74.1)和数字(53.9)时可以观察到最大的差异。这是意料之中的,因为数字非常具体,通常很难概括。然而,软精度度量和示例(附录C)表明,该模型相对擅长预测至少接近目标的数字。
Limitations
TAPAS将单个表作为上下文处理,这些上下文能够适应内存。因此模型将无法捕获非常大的表,或者包含多个表的数据库。对于这种情况,可以对表进行压缩或过滤让相关的内容被编码,我们留待以后的工作。
此外,尽管TAPAS可以解析组成结构(例如图3中的问题2),但它的表达能力仅限于表单元格子集上的聚合形式。因此,模型无法正确处理具有多个聚合结构的问题,如“平均评级高于4的参与者数量”。尽管有这种限制,TAPAS成功地解析了三个不同的数据集,我们在第5.3节中没有发现这种错误。这表明当前语义解析数据集中的大多数示例在聚合结构上是受限的。
Related Work
语义解析模型主要是使用编码器-解码器方法来训练产生黄金逻辑形式(Jia and Liang, 2016; Dong and Lapata, 2016)。为了减轻标注完整逻辑格式的成本,模型通常在弱监督中用表达结果的形式训练,用这种方式来指导寻找正确的逻辑格式(Clarke et al., 2010; Liang et al., 2011).。
其他工作建议从弱监督训练端到端可微模型,但不显式生成逻辑形式。Neelakantan等人(2015)提出了一个复杂的模型,该模型按顺序预测所有作者明确预定义的表段上的符号操作,而Yin等人(2016)提出了一个类似的模型,其中操作符号本身是在训练期间学习到的。Muller等人(2019)提出了一个选择表单元格的模型,其中表和问题表示为图形神经网络,但是他们的模型不能预测表单元格上的聚合操作。Cho等人(2018)提出了一个监督模型,该模型按顺序预测相关的行、列和聚集操作。在我们的工作中,我们提出了一个遵循这一工作路线的模型,其架构比过去的模型更简单(因为该模型是一个单独的编码器,隐式地执行许多操作的计算),并且覆盖范围更大(因为我们支持选定单元上的聚合运算符)。
最后,设计了具有不同训练目标的预训练方法,包括语言建模(Dai and Le,2015年;Peters et al,2018年;Raford et al,2018年)和掩蔽语言建模(Devlin et al,2019年;Lample and Conneau,2019年)。这些方法极大地提高了自然语言理解模型的性能。最近,一些作品通过对文本-图像对进行预训练,同时掩蔽图像中的不同区域,扩展了BERT用于视觉问题回答。至于表格,Chen等人(2019)尝试将表渲染成自然语言,以便可以用预先训练的BERT模型来处理。在我们的工作中,我们通过掩蔽表单元格或文本段来扩展表表示的掩蔽语言建模。
Conclusion
在本文中,我们提出了TAPAS,一个避免生成逻辑形式的表格问答模型。我们证明了TAPAS能够有效地对文本表对的大规模数据进行预训练,并能成功恢复掩蔽的单词和表单元格。我们还证明了该模型通过端到端的可微方式预训练,可以微调后用于语义解析数据集。结果表明,与最先进的语义解析器相比,TAPAS取得了相同或更好的结果。
在未来的工作中,我们准备将模型扩展到以多个表作为上下文的数据库上,并使其能够有效地处理大型表。
Appendix
聚合操作符的可微结构

软准确率计算方式