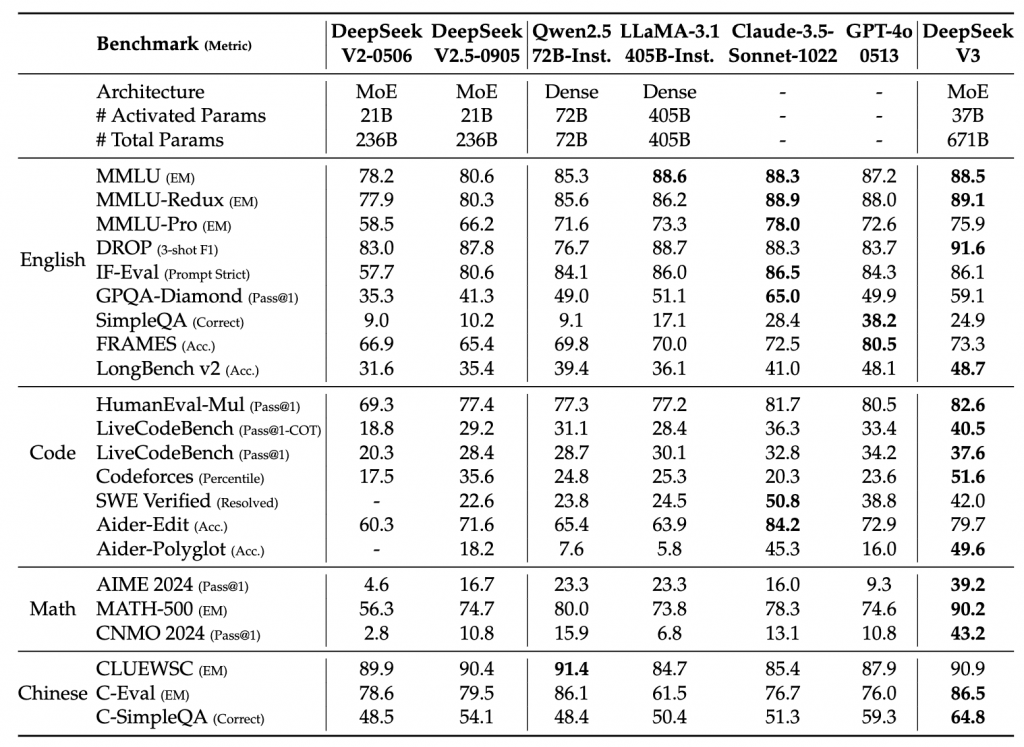
Abstract
MoE 671B -> 37B
Multi-head Latent Attention
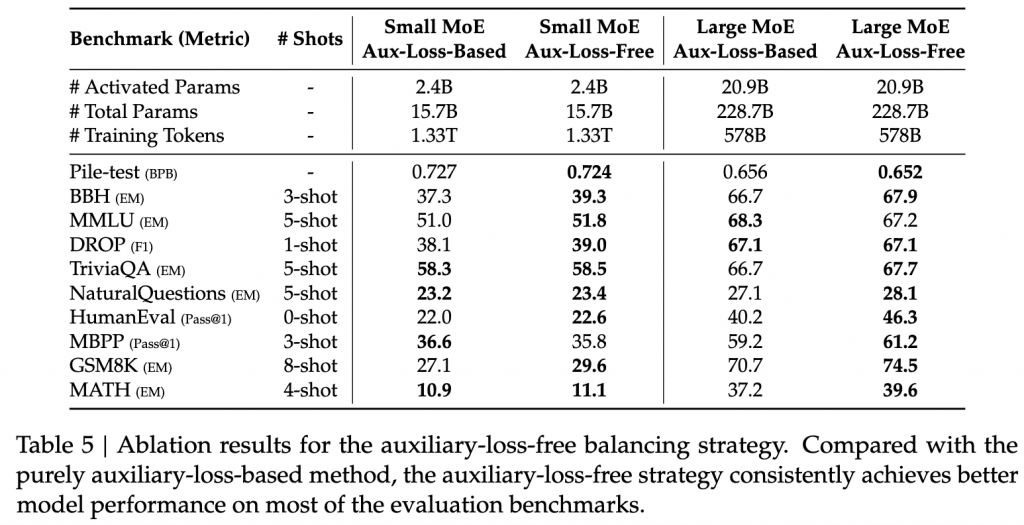
auxiliary-loss-free strategy
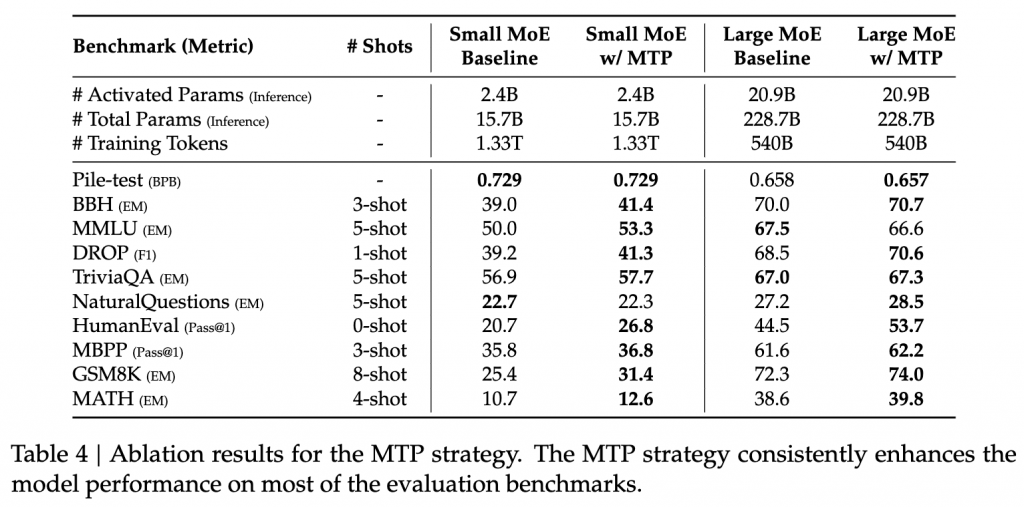
a multi-token prediction training objective
Pre-Training Context Extension Post-Training
Architecture
Multi-head Latent Attention (MLA)
已有工作如何减小注意力机制的缓存
LLM模型多采用多头注意力机制,传统推理时,每次都需要计算t次q、k、v(t表示第t个token),但不难发现,q只需计算当前token即可,前t-1个token的k和v都是重复计算,所以我们可以将k和v缓存起来,大大减少计算量。
传统的KV cache通过缓存key、value,从而不必每次重新计算,提高推理速度。但是在推理过程中,随着序列长度的不断增加,KV cache会越来越大,访问的开销也越来越大,已然成为了目前限制推理速度的瓶颈。
目前解决方法:MQA、GQA
MHA:为每个注意力头都存一组k、v,内存开销:2✖️nd✖️ntoken✖️dh✖️l,不存在精度损失
MQA:所有注意力头共享一组k、v,内存开销:2✖️ntoken✖️dh✖️l,精度损失较大
GQA:对注意力头进行分组,每组共享一组k、v,内存开销:2✖️ng✖️ntoken✖️dh✖️l,这是MHA和MQA的折中方案,精度损失也介于MHA和GQA之间

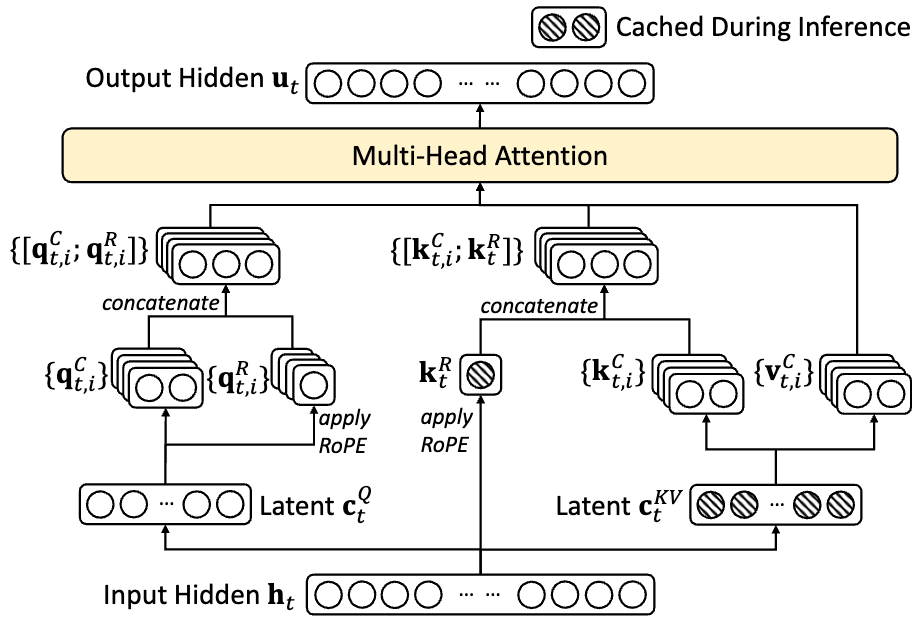
Input Hidden Demension=7168
number of attention heads = 128, head dimension = 128
KV compression dimension 𝑑𝑐 = 512, and the query compression dimension 𝑑′𝑐 = 1536
per-head dimension 𝑑𝑅ℎ = 64
基本思路:不直接存储k、v,而是将其低维压缩后再进行存储,使用时,再将其映射回原始k、v维度,类似于对KV cache做LoRA。
Q1:缓存Latent Ckv 而不是KV,虽然减小了缓存尺寸,但在每次计算时候,需要重复计算KV,增加了计算量?
- 推理访存密集,对kv缓存的优化能带来很大收益;计算这边attention量还好
Q2:Q和K经过RoPE后,已经包含了语意+位置信息,为什么还需要与自身concatenate?
- K的RoPE是从Input Hidden计算的,由于Kc是压缩后的潜在语意空间,如果走RoPE会破坏潜在的表达,因此最终方案使用在Kc后面拼接位置信息。
- Q是从Latent中提取的,如果直接过RoPE,可能会破坏潜在表达?
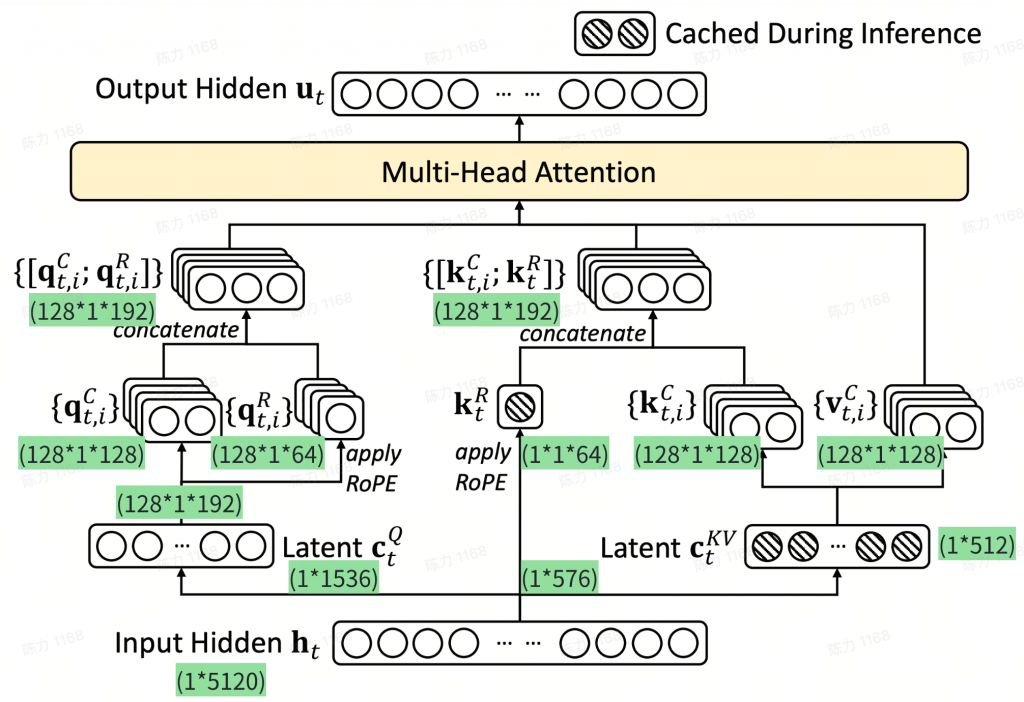
其他尝试的解法
MLA之所以能保持跟GQA一样大小的KV cache,其关键一步是将W^{Q}W^{UK}合并为一个(跟位置无关的)矩阵W^{Q\_UK}作为q的投影矩阵,但如果加了RoPE的话,这一步就无法实现了。这是因为RoPE是一个跟位置相关的d_h\times d_h的分块对角矩阵R_m,满足R_mR_n^T = R_{m-n},MLA加入RoPE之后会让W^{Q}W^{UK}中间多插入了一项R_{t-i}:\mathbf{q}_t = \mathbf{h}_tW^{Q}R_t, \quad \mathbf{k}_i = \mathbf{c}_i^{KV}W^{UK}R_i\mathbf{q}_t(\mathbf{k}_i)^T = \mathbf{h}_tW^{Q}R_t(\mathbf{c}_i^{KV}W^{UK}R_i)^T = \mathbf{h}_tW^{Q}R_{t-i}(W^{UK})^T(\mathbf{c}_i^{KV})^T
这里的W^{Q}R_{t-i}(W^{UK})^T就无法合并为一个固定的投影矩阵了(跟位置差t-i相关),从而MLA的想法无法结合RoPE实现。
一个naive的解决思路是:在重算\mathbf{k}_t^{C}后再添加RoPE,但这样访存效率会很低,因为普通MHA只是简单读取KV Cache就已经达到瓶颈,现在还需要读取投影并加上RoPE
其他解决方案:
放弃RoPE,换用其他基于Attention Bias的位置编码,如ALIBI–>效果明显不如RoPE
将\mathbf{q}_t的输入也改为\mathbf{c}_t^{KV},然后将RoPE加在\mathbf{c}_t^{KV}之后,即:\mathbf{q}_t = \mathbf{c}_t^{KV}R_tW^{UQ'}, \quad \mathbf{k}_i = \mathbf{c}_i^{KV}R_iW^{UK}
不过此时的RoPE不再是通过绝对位置实现相对位置,而单纯是加在q、k上的绝对位置信息,让模型自己想办法提炼相对位置信息。(简单理解:\mathbf{q}_t(\mathbf{k}_i)^T后,得不到R_{t-i})
RoPE
https://arxiv.org/abs/2104.09864 提出了对Transformer中Multi-Head Attention改造,增加相对位置信息
DeepSeekMoE
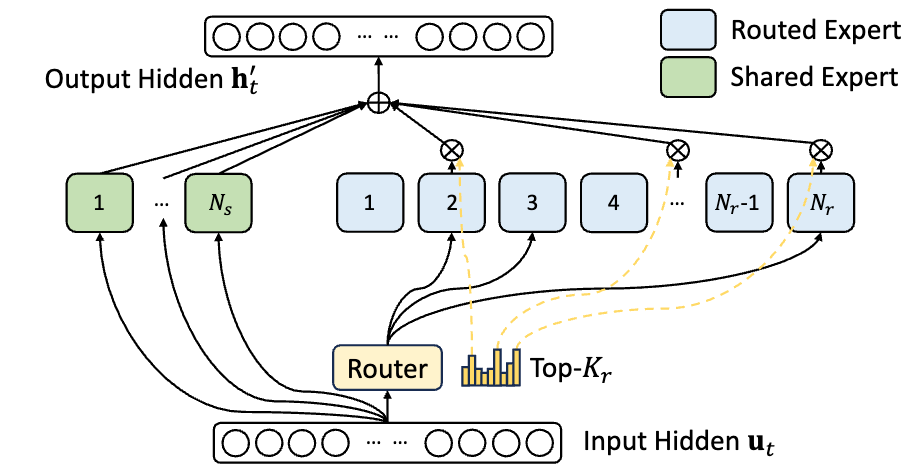
DeepSeekMoE改造FFN层,使用1个共享专家和256选9个路由专家,每个专家的hidden dimension = 2048。
auxiliary-loss-free strategy
Router 选择 Top-k时,每个专家有一个b的偏置分数。
b在每个step后更新,通过计算经过每个专家的token数量,将其减去均值,乘以𝛾,得到需要更新的值。
Complementary Sequence-Wise Auxiliary Loss
一个损失函数,促进专家在句子粒度上的平衡。
Multi-Token Prediction (MTP)
https://openreview.net/forum?id=pEWAcejiU2
Different from Gloeckle et al. (2024), which parallelly predicts 𝐷 additional tokens using independent output heads, we sequentially predict additional tokens and keep the complete causal chain at each prediction depth.
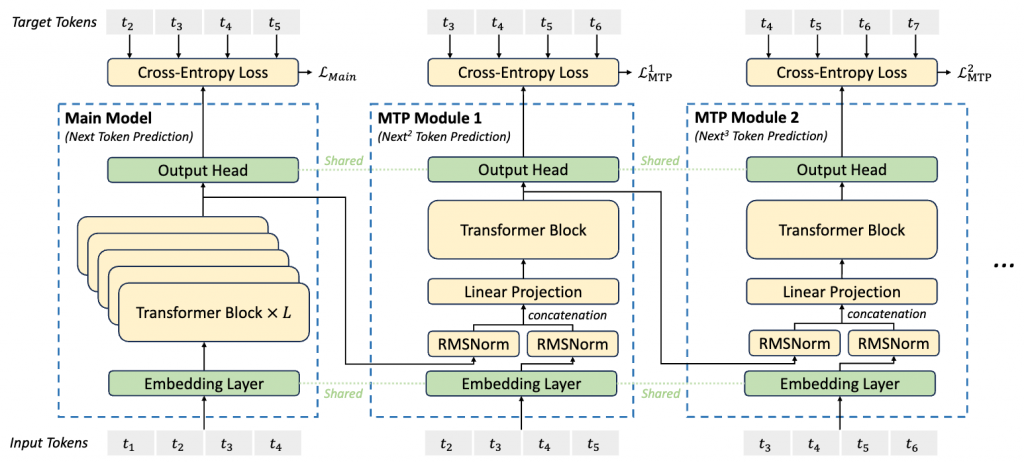
- Embedding Layer 和 Output Head是共享的
- Loss Function 仍然是交叉墒损失,乘系数lambda(0.3->0.1)
- 主要用于提升main model的性能,训练时额外预测1个token,推理时不使用,但也可以用于推理解码
RMSNorm
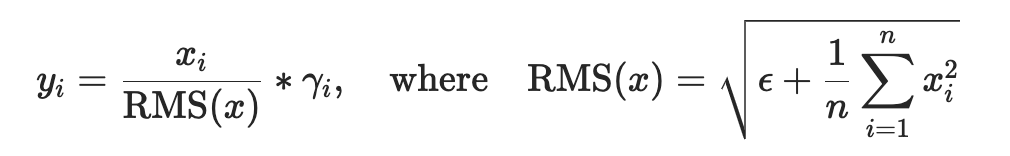
- 近期很多LLMs使用 RMSNorm 替代 LayerNorm,主要原因是效果差不多且节约显存带宽
Infrastructures
2048块H800
自研HAI-LLM Framework
FP8训练
Mixed Precision Framework
Increasing Accumulation Precision
略过大量讲解低精度优化的工作
Pre-training
Fill-in-Middle (FIM) strategy
Tokenizer:Byte-level BPE + extended vocabulary of 128K tokens
Long Context Extension
After the pre-training stage, apply YaRN to expand the context window from 4K to 32K and then to 128K.
Post-training
SFT
共150w示例
Reasoning Data:与推理相关的数据集,包括那些专注于数学、编程竞赛问题和逻辑谜题的数据集。
- 为每个任务开发一个专家模型,在训练过程中,为每个实例生成两种不同类型的SFT样本:
- 类型1:将问题与其原始响应配对,格式为
<问题, 原始响应>。 - 类型2:将系统提示与问题及R1响应组合,格式为
<系统提示, 问题, R1响应>。
- 类型1:将问题与其原始响应配对,格式为
- 强化学习阶段,模型利用高温度采样(high-temperature sampling)生成响应,使其能够在没有明确系统提示的情况下整合R1生成的数据和原始数据的模式。经过数百步的RL训练之后,模型学会了采用R1模式,从而战略性地提升整体性能。
- 实施拒绝采样(rejection sampling)以获取高质量的SFT数据供最终模型使用。
Non-Reasoning Data:创意写作,角色扮演和简单问题回答,我们利用DeepSeek-V2.5生成回答,并人工验证数据的准确性和正确性。
SFT:2 epoch,lr 5x10e-6 -> 10e-6
During training, each single sequence is packed from multiple samples. However, we adopt a sample masking strategy to ensure that these examples remain isolated and mutually invisible. ???
RL
组合使用基于规则的奖励模型+基于model奖励模型
通过在给予最终奖励时包含COT解释,可以减轻reward hacking
GRPO策略
Evaluation