SwAV https://arxiv.org/pdf/2006.09882.pdf
DINO https://arxiv.org/pdf/2104.14294.pdf
Abstract
无监督图像表示显著缩小了与有监督预训练的差距,尤其是对比学习方法的在近期成就突出。这些对比方法通常是在线学习并依赖计算大量显式成对特征,因此在计算上具有挑战性。在本文中,我们提出了一种在线算法 SwAV,它利用对比方法而不需要计算成对比较。具体来说,我们的方法同时对数据进行聚类,同时加强为同一图像的不同增强(或“视图”)产生的聚类分配之间的一致性,而不是像对比学习那样直接比较特征。简而言之,我们使用“交换”预测机制,我们从另一个视图的表示中预测一个视图的代码。我们的方法可以用大批量和小批量进行训练,并且可以扩展到无限量的数据。与之前的对比方法相比,我们的方法内存效率更高,因为它不需要大的内存库或特殊的动量网络。此外,我们还提出了一种新的数据增强策略 multi-crop,它使用具有不同分辨率的混合视图代替两个全分辨率视图,而不会增加内存或计算要求。我们使用 ResNet-50 在 ImageNet 上实现 75.3% 的 top-1 准确率,并在所有考虑的传输任务上超越监督预训练。
Introduction
我们提出了一种可扩展的在线聚类损失,它在 ImageNet 上将性能提高了 2%,并且可以在没有大内存库或动量编码器的情况下在大batch和小batch设置中工作。
我们引入了multi-crop策略来增加图像的视图数量,而没有计算或内存开销。 我们观察到在 ImageNet 上使用这种策略在几种自监督方法上有 2% 到 4% 的持续改进。
将这两种技术贡献结合到一个模型中,我们在 ImageNet 上使用标准 ResNet 将自监督的性能提高了 4.2%,并在多个下游任务上优于有监督 ImageNet 预训练。 这是第一种仅在冻结特征之上使用线性分类器的无需微调特征的方法。
Method
典型的基于聚类的方法是离线的,因为需要聚类步骤和训练步骤交替进行。
在本节中,我们将描述一种替代方法。使同一图像在不同增强后的code强行一致。 该解决方案的灵感来自对比实例学习,因为我们不将code视为目标,而仅在同一图像的视图之间强制执行一致映射。 我们的方法可以解释为一种通过比较它们的集群分配而不是它们的特征来对比多个图像视图的方法。
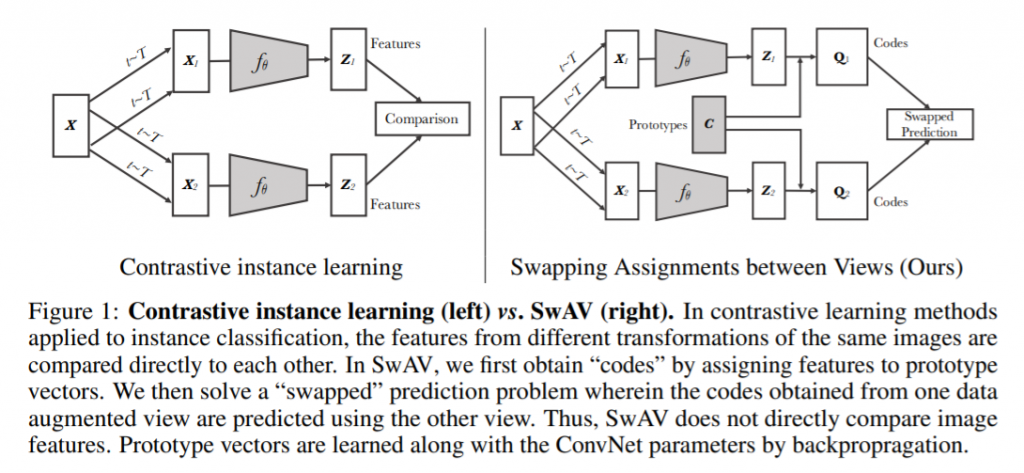

对于同一张图像,进行不同增强后得到的两个特征
z_t,z_s,通过与聚类簇K∈{c_1, c_2, ... c_k}的计算得到code记为q_t,q_s,L(z_t, z_s) = loss(z_t, q_s) + loss(z_s, q_t)
为了使我们的方法能在线训练,我们仅使用batch中的图像特征来计算代码。 直观地说,由于聚类簇C跨不同批次使用,SwAV 会将多个实例聚集到聚类簇C中。 我们使用聚类簇C计算代码,使得batch中的所有示例都由原型等分。 这种均分约束确保批次中不同图像的代码是不同的,从而防止每个图像具有相同代码。
网络原理
P
τ_s > 0 a temperature parameter that controls the sharpness of the output distribution
Loss
We follow the data augmentations of BYOL (color jittering, Gaussian blur and solarization) and multi-crop with a bicubic interpolation.
Given image x, we generate a set V of different views, while x_1, x_2 in V are global views and others x’ are local views by using multi-crop.
Centering
Centering prevents one dimension to dominate but encourages collapse to the uniform distribution, while the sharpening has the opposite effect.
Teacher network
We build it from past iterations of the student network and study different update rules.
Network architecture
Backbone: ViT or ResNet + a projection head + l2norm + fc(K dimensions)
The projection head starts with a n-layer(3) multilayer perceptron (MLP). The hidden layers are 2048d and are with gaussian error linear units (GELU) activations.
网络效果
For linear evaluations, we apply random resize crops and horizontal flips augmentation during training, and report accuracy on a central crop.
For finetuning evaluations, we initialize networks with the pretrained weights and adapt them during training. For k-nn evaluations, we freeze the pretrain model to compute and store the features of the training data of the downstream task. The nearest neighbor classifier then matches the feature of an image to the k(=20) nearest stored features that votes for the label.
ImageNet Top-1 Accuracy on V100
Image retrieval
DAVIS 2017 Video object segmentation
Transfer learning by finetuning pretrained models
总结
k-NN分类中特征的质量有可能用于图像检索
在特征中存在关于场景布局的信息也有利于弱监督图像分割
我们的证据表明,自监督学习可能是开发基于ViT的类BERT模型的关键
![[略读]Twins系列](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)
图片不显示了
已补~