UNiversal Image-TExt Representation Learning
Abstract
联合图文嵌入是大多数视觉和语言任务(V+L tasks)的基础,在这些任务中,多模态输入被同时处理以进行组合视觉和文本的理解。本文介绍了Uniter,一种通用的图文表示方法,它在四个图文数据集(COCO、Visual Genome、Concept Captions和SBU Captions)上进行大规模预训练,可以为各种下游V+L任务提供联合多模态的能力。我们设计了四个预训练任务:掩码语言建模(MLM)、掩码区域建模(MRM及其三种变体)、图文匹配(ITM)和词区域对齐(WRA)。与以往将联合掩码随机应用于两种模态的工作不同,我们在预训练任务中使用条件掩蔽(即掩蔽的语言/区域建模是以对图像/文本的充分观察为条件的)。除了ITM用于全局图文对齐外,我们还提出了WRA,通过使用最优传输理论(Optimal Transport,OT)来显式地鼓励在预训练期间单词和图像区域之间的细粒度对齐。综合分析表明,条件掩码和基于最优传输理论的WRA都有助于更好的预训练。我们还进行了完整的消融研究,以找到预训练任务的最佳组合。广泛的实验表明,Uniter在6个V+L任务(超过9个数据集)上达到了新的水平,包括视觉问答、图文检索、参考表达理解、视觉常识推理、视觉蕴涵和NLVR。
Introduction
大多数视觉和语言任务都依赖联合多模型嵌入来弥合图像和文本的语义鸿沟,而此类表示通常是为特定任务量身定制的。 例如,MCB、BAN和DFAF提出了用于视觉问题回答(VQA)的高级多模式融合方法。SCAN和MAttNet学习单词和图像区域之间的潜在对齐,用于图像文本检索和参照表达理解。尽管这些模型都在各自的领域达到了SOTA,但它们的体系结构却是不同的,并且学习到的表示形式是高度特定于任务的,难以将其推广到其他任务。这就提出了一个很重要却难以回答的问题(the million-dollar question):我们能否为所有V + L任务训练通用的图文表达形式?
因此我们为多模态联合编码提出大尺度预训练模型UNITER,将Transformer作为模型核心,利用其优美的自注意力设计学习语境化表示。BERT通过大尺度语言模型成功将Transformer应用于NLP任务中,受其启发我们在四个预训练任务上完成UNITER的预训练:
- Masked Language Modeling (MLM) conditioned on image
- Masked Region Modeling (MRM) conditioned on text,为了进一步挖掘其有效性,提出三种变体:
- Masked Region Classification (MRC)
- Masked Region Feature Regression (MRFR)
- Masked Region Classification with KL-divergence (MRC-kl).
- Image-Text Matching (ITM)
- Word-Region Alignment (WRA)
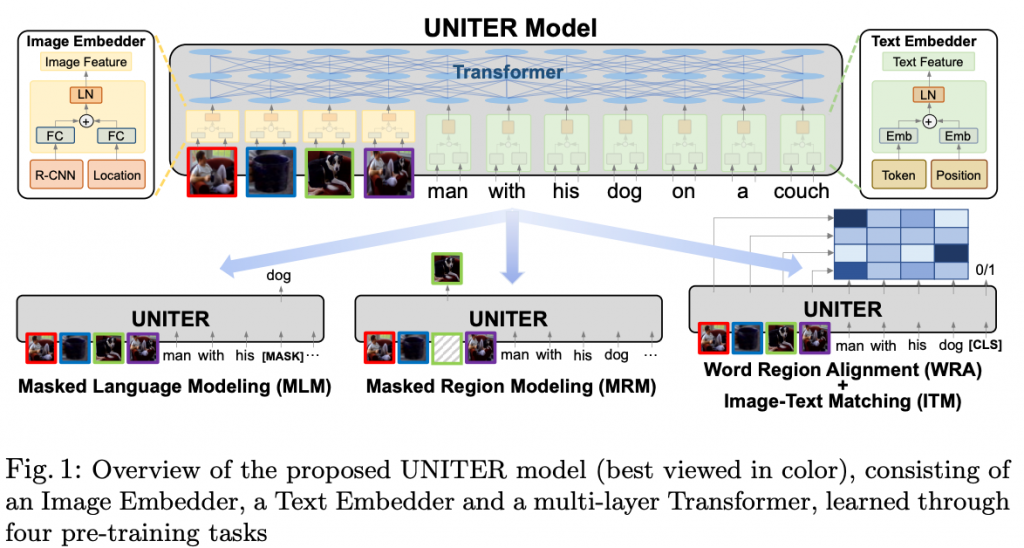
如图1所示,UNITER首先将图像区域(视觉特征和目标框特征)和文本单词(tokens和位置)编码到有图像编码和文字编码的共同的嵌入空间。然后通过精心设计的预训练任务,使用Transformer模块学习每个区域和每个单词的广义语义编码。与之前的多模态预训练工作相比,我们以图像/文本的全面观察为条件,而不是对两种模态的联合随机遮掩;提出WRA预训练任务时用最优传输理论鼓励文本和图像区域的细粒度对齐。直观来看,基于最优传输理论的学习旨在通过最小化转移一个到另一个的成本优化分布匹配。在本文中,我们最小化从图像区域到句中文字的嵌入编码转换成本,从而实现更优的跨模态对齐。我们发现,条件掩蔽和基于最优传输理论的WRA都可以成功地缓解图像和文本之间的不对齐,从而为下游任务提供更好的联合嵌入。
为了展示UNITER的通用能力,我们评估了9个数据集中的6个V + L任务,包括:
- VQA
- 视觉常识推理(VCR)
- NLVR2
- 视觉约束
- 图像文本检索(包括zero-shot设置)
- 引用表达理解
UNITER模型是在由四个子集组成的大规模V + L数据集上训练的:
- CoCo
- 视觉基因组VG
- 概念字幕(CC)
- SBU字幕
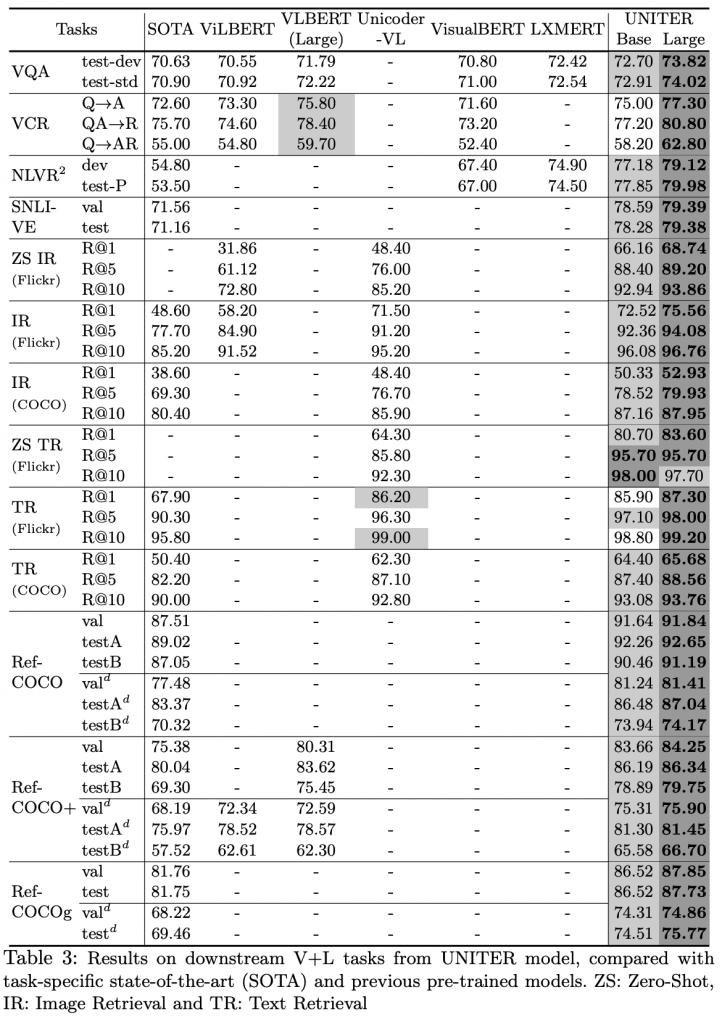
实验表明,UNITER在所有九个下游数据集上的性能都有了显着提高,从而达到了新的水平。 此外,与仅使用COCO和VG数据进行训练相比,附加CC和SBU数据的训练进一步提高了模型性能(在下游任务中包含看不见的图像/文本)。
我们的贡献总结如下:
- 我们推出UNITER,这是一种用于V + L任务的功能强大的图像文本通用表示法
- 我们提出了用于掩码语言/区域建模的条件掩码,并提出了一种新颖的基于OT的词域对齐任务以进行预训练。
- 我们在各种V + L基准上取得了SOTA,大大超过了现有的多模态模型。我们还进行了广泛的实验和分析,对每个预训练任务/数据集的多模态编码器训练提出有效见解。
Related Work
自我监督学习利用原始数据作为自己的监督源,该方法已应用于许多计算机视觉任务,例如图像整理,解决拼图,修复,旋转谓词和相对位置预测等等。最近预训练的语言模型,例如ELMo,BERT,GPT2,XLNet,RoBERTa和ALBERT ,在NLP任务方面取得了长足的进步。 它们成功的关键有两个:在大型语言语料库上进行有效的预训练任务,以及使用Transformer学习带上下文语义的文本表示形式。
最近,人们开始对多模态任务进行自监督学习,先在大型图像/视频或文本对上进行预训练,然后在下游任务进行微调。例如,VideoBERT和CBT应用BERT来从视频-文本对中学习视频帧特征和语言标记的联合分布。 ViLBERT和LXMERT 引入了双流体系结构,其中两个Transformer分别应用于图像和文本,在稍后的阶段由第三个Transformer融合。在另一方面,B2T2,VisualBERT,Unicoder-VL和VL-BERT提出了单流体系结构,将单个Transformer应用于图像和文本。VLP 将预训练的模型应用于图像字幕和VQA。最近,多任务学习和对抗训练用于进一步提高性能,VALUE开发了一组探测任务以了解预训练的模型。
UNITER模型与其他方法之间的区别主要在两个方面:
- UNITER在MLM和MRM上使用条件掩蔽,即仅掩盖一种模态,同时保持另一种模态不变;
- 使用最优传输理论实现一种新颖的单词-区域对齐的预训练任务,而在之前的工作中,这种对齐仅由特定于任务的损失隐式地强制执行。
此外,通过彻底的消融研究来检查预训练任务的最佳组合,并在多个V + L数据集上达到SOTA,比先前的工作有明显提升。
UNiversal Image-TExt Representation
在本节中,我们首先在第3.1节介绍UNITER的模型架构,然后在第3.2和3.3节描述设计的预训练任务和用于预训练的V + L数据集。
3.1 Model Overview
模型结构如图1,给定一对图像和句子,UNITER将视觉区域和句中文本token作为输入,我们设计了Image Embedder和Text Embedder来提取嵌入编码,这些编码送入多层Transformer来学习视觉区域和文本token的跨模态上下文编码。需要注意的是Transformer中的自注意力机制是无序的,因此需要将token的位置和region的定位作为额外输入。
对于Image Embedder,首先使用Faster RCNN提取每个区域的视觉特征(pooled ROI features),将特征定位编码为7维特征向量,然后将视觉特征和定位特征送入全连接层映射至相同编码空间。最终每个区域的视觉编码为两个全连接层的输出相加,再经过LN层。对于Text Embedder,我们使用BERT将输入的句子切分为词向量,最终每个分词token的表达为词编码和位置编码之和,再经过LN层。
我们介绍了四个主要任务来预训练我们的模型:基于图像区域(MLM)的掩码语言建模,基于输入文本(具有三个变体)(MRM),图像-文本匹配(ITM)和单词区域对齐(WRA)的掩码区域建模。如图1所示,我们的MRM和MLM与BERT类似,在BERT中,我们从输入中随机掩盖了某些单词或区域,并学习恢复这些单词或区域作为Transformer的输出。具体来说,通过用特殊令牌[MASK]替换token来实现单词屏蔽,通过用全零替换视觉特征向量来实现区域屏蔽。请注意,每次我们只掩盖一个模态而保持另一个模态不变,而不是像其他预训练方法那样随机掩盖两个模态。这防止了当被遮挡区域正好被遮挡单词描述时的潜在不匹配情况(详见第4.2节)。
我们还通过ITM学习了整个图像与句子之间的实例级对齐。在训练过程中,我们采样图像和句子对的正负例,学习它们的匹配分数。此外,为了在单词标记和图像区域之间提供更细粒度的对齐方式,我们提出使用OT的WRA,它有效计算出上下文image embedding转换为word embedding的最低成本(反之亦然),而这推动了更好的跨模态对齐。从经验上讲,我们表明条件屏蔽和WRA都有助于提高性能(在第4.2节中)。为了使用这些任务对UNITER进行预训练,我们为每个小批量随机抽取一个任务,并且每次SGD更新仅针对一个目标进行训练。
3.2 Pre-training Tasks
MLM:图像区域v={v1, …, vk},句子w={w1, …, wT},对文本按15%概率降wm替换为特殊标记[MASK]
ITM:增加一个额外的特殊标记[CLS],表示两种模态的融合。输入为一个句子和一系列图像区域,输出为二进制标签0或1,表明样本对是否匹配。ITM监督是通过[CLS]token进行的。在训练期间,我们在每一步中都从数据集D中对正对或负对(w,v)进行采样。否定对是通过将配对样本中的图像或文本替换为其他样本中随机一个来创建的,损失函数应用二进制交叉熵损失。
WRA:使用最优传输理论,训练传输向量T(RT✖️K)来优化w和v之间的对齐,(w, v)可以看作是两个离散概率分布µ、ν,(略)使用IPOT算法估计OT距离,将其作为WRA的损失。有几个好处:
- 自归一化:T的所有元素之和为1
- 稀疏性:当精确求解时,OT产生的稀疏解T最多包含(2r-1)个非零元素,其中r = max(K, T),更易解释和更可靠的对齐
- 效率:与传统的线性规划求解器相比,我们的解决方案可以使用仅需要矩阵向量乘积的迭代程序轻松获得,因此易于应用于大规模模型预训练
MRM:对图像区域进行采样并以15%概率遮掩其视觉特征,训练模型在给定其他区域和所有单词的情况下重建掩码区域,Mask区域的视觉特征使用0填充。由于视觉特征是高维且连续的,不像文本token那样表示为离散标签,因此不能使用分类方式,本文提出三种MRM的变形,共享相同的目标:
- Masked Region Feature Regression (MRFR):使用FC层将Transformer输出转换为输入ROI pooled feature尺寸的向量,并用L2回归计算损失。
- Masked Region Classification (MRC):使用FC层将Transformer输出转换为K个目标类别的分数,然后经过softmax。由于没有ground-truth,我们使用Faster RCNN的输出类别作为标注,将其转为one-hot向量,计算CE loss。
- Masked Region Classification with KL-Divergence (MRC-kl):使用Faster RCNN的直接输出作为软标签,计算两个分布的KL散度。
3.3 Pre-training Datasets
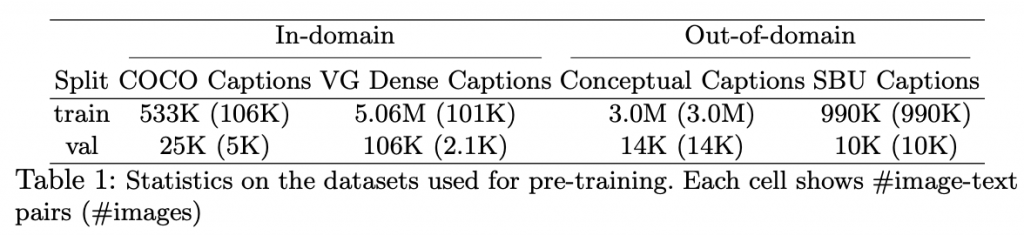
为了研究不同数据集对预训练的影响,我们将四个数据集分为两类。 第一个由来自COCO的图像字幕数据和来自VG的密集字幕数据组成。 我们将其称为“域内”数据,因为大多数V + L任务都建立在这两个数据集之上。为了获得“公平”的数据划分,我们将COCO的原始训练和验证划分合并,并排除了出现在下游任务中的所有验证和测试图像。我们还通过URL匹配排除了所有同时出现的Flickr30K图像,因为COCO和Flickr30K图像都是从Flickr抓取的,并且可能有重叠。同样的规则也适用于Visual Genome。这样,我们获得了用于训练的560万个图像-文本对和用于内部验证的131K个图像-文本对,这是LXMERT中使用的数据集大小的一半,这归因于对重叠图像的过滤和使用。仅图像-文本对。我们还使用来自Conceptual Captions和SBU Captions的其他域外数据进行模型训练。表1提供了清理后的拆分的统计信息。
Experiments

Conclusion
在本文中,我们介绍UNITER,这是一种大规模的预训练模型,可为视觉和语言任务提供通用的表示。提出了四个主要的预训练任务,并通过广泛的消融研究对其进行了评估。在域内和域外数据集的训练下,UNITER在多个V + L任务上以相当大的优势达到了SOTA。未来的工作包括研究原始图像像素和句子标记之间的早期交互,以及开发更有效的预训练任务。
![[略读]Sequence Transduction with Recurrent Neural Networks](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)