GRPO
KL散度的近似估算方式
在 R1 的 GRPO 中,KL 散度直接通过采样数据计算:
\hat{D}{KL} \approx \frac{1}{N}\sum{i=1}^N \log\left(\frac{\pi_\theta(o_i|q)}{\pi_{ref}(o_i|q)}\right)
这种方法在 (\pi_\theta(o_i|q) \ll \pi_{ref}(o_i|q))(当前策略采样某动作的概率远低于参考策略)时,会导致梯度权重无界放大,引入大量噪声,破坏训练稳定性。
V3.2 采用修正 K3 估算器,通过重要性采样比率修正 KL 散度的计算,公式为:
D_{KL}\left(\pi_{\theta}\left(o_{i, t}\right) | \pi_{ref}\left(o_{i, t}\right)\right)=\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<<t}\right)}{\pi_{old}\left(o_{i, t} | q, o_{i,<<t}\right)}\left(\frac{\pi_{ref}\left(o_{i, t} | q, o_{i,<<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<<t}\right)}-log \frac {\pi_{ref}\left(o_{i, t} | q, o_{i,<<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<<t}\right)}-1\right)
其中 (\frac{\pi_\theta}{\pi_{old}}) 是重要性采样权重,用于修正采样分布与目标分布的偏差。
增加Off-Policy掩码
为解决大规模强化学习训练中 Off-Policy问题而设计的核心优化手段,本质是过滤掉训练中 “有害且不可靠” (负优势、高分歧)的样本,只保留有效学习信号,从而大幅提升 GRPO 算法的训练稳定性。
Off-Policy:用旧策略πold 采样的数据,训练新策略πθ(数据和策略 “不同步”)。
MOE优化
记录推理时专家路由,训练强制复用,确保梯度更新目标一致
Deepseek-3.2
基于蒸馏数据训练的模型性能仅略低于领域专用专家模型,且通过后续的强化学习训练,这一性能差距可有效消除
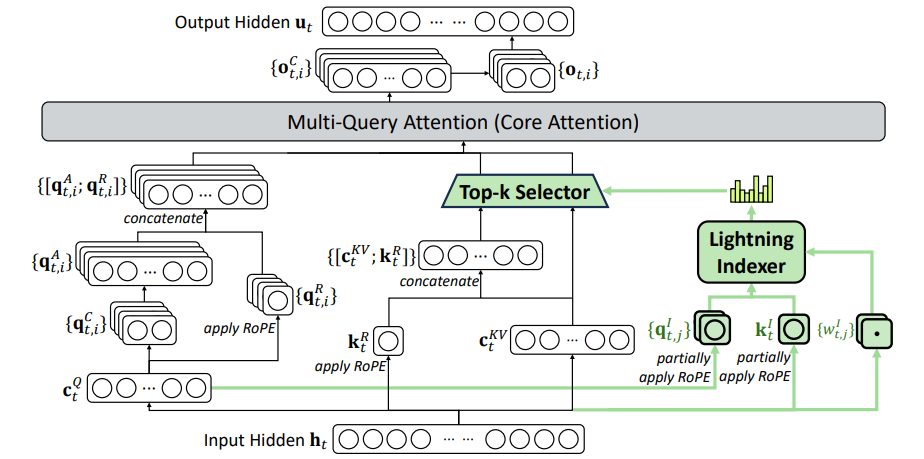
DSA稀疏注意力机制