Twins: Revisiting the Design of Spatial Attention in Vision Transformers
Conditional Positional Encodings for Vision Transformers
主要贡献
Conditional Positional Encodings
Table12 通过实验证实相对位置关系的重要性,发现将PVT的绝对位置编码修改为相对位置关系后,PVT性能比肩Swin-Transformer。
提出Positional Encoding Generator(PEG)生成位置编码信息。将feature tokens 变形还原至HxWxC的维度,使用卷积生成相同尺度的特征图,将特征图变形至token的维度,作为position encoding使用。
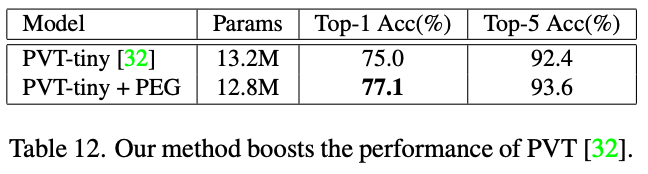
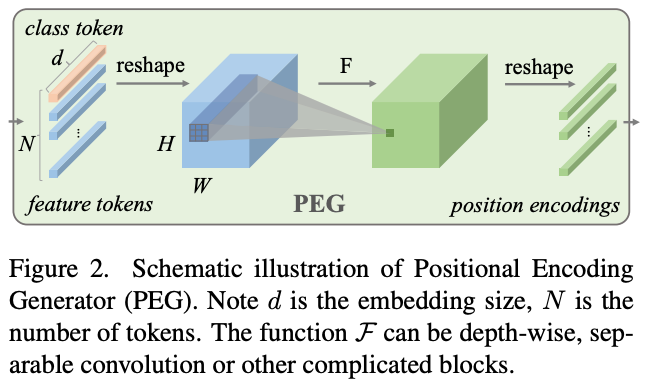
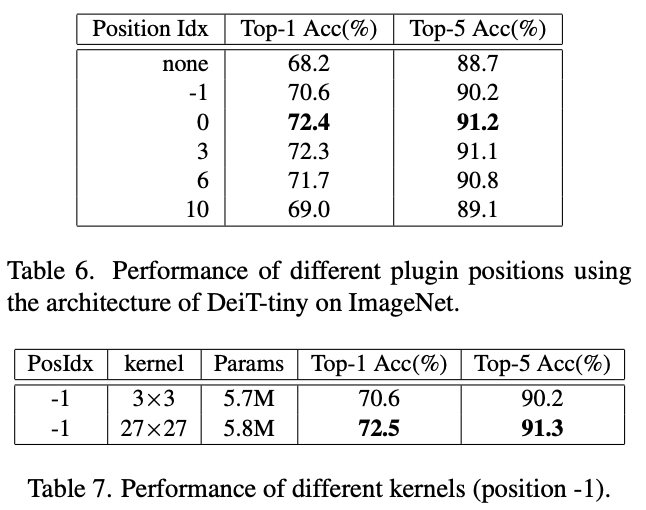
Table6 探究了PEG在不同位置的结果,-1表示放在第一个encoder前,0表示放在第一个encoder后,3表示放在第三个encoder后。
Table7 探究了为何PEG放在-1位置效果不够好,原因是-1位置需要更广的相对位置编码,使用27×27的卷机核即可。
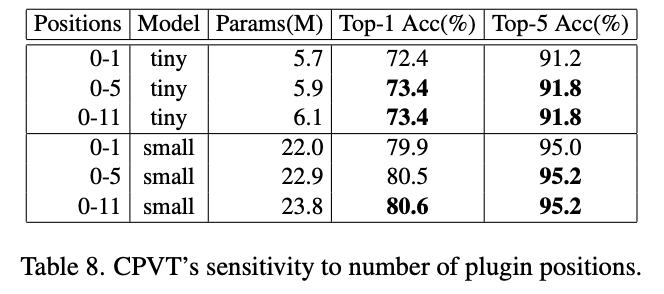
Table8 探究了应该放多少PEG
Table10 发现如果PEG中的卷机操作如果不使用PAD,效果会下降,猜测是因为分类标签与图像中心目标强相关,因此网络需要一些绝对位置信息来。

SVT结构
LSA+GSA+每层PEG,效果比Swin略好
| Method | Param(M) | GFLOPs | Top-1 Err |
| Swin-T | 29 | 4.5 | 18.7 |
| Twins-SVT-S | 24 | 2.8 | 18.3 |
| Swin-S | 50 | 8.7 | 17.0 |
| Twins-SVT-B | 56 | 8.3 | 16.8 |
| Swin-B | 88 | 15.4 | 16.7 |
| Twins-SVT-L | 99.2 | 14.8 | 16.3 |
Locally-grouped self-attention (LSA)
与Swin-Transformer相同,将特征图分为M✖️N块,做局部self-attention。
Global sub-sampled attention(GSA)
将特征图变形为M✖️N个vector,做self-attention。
