Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Embedding
使用[EOS]对应的hidden state作为embedding
{Instruction} {Query}<|endoftext|>使用改进的InfoNCE Loss进行训练
- 分子S = query 和 正例的余弦相似度
- 分母Z = S + query和难负样本的余弦相似度+batch内正例与其它query的余弦相似度+batch内query与其它文档的余弦相似度
- 温度系数
- 防止假负例:相似度>S+0.1
大规模合成数据的弱监督训练
- 任务类型:检索(Retrieval)、双语对齐(Bitext mining)、语意相似度(STS, semantic textual similarity)、分类(classification)
- 查询重写:角色库top5的角色放入提示词中,提示词涵盖查询类型、查询长度、难度、语言等
- 1.5亿对进行预训练,1200万高质量进行SFT
重写Prompt
Given a **Character**, **Passage**, and **Requirement**, generate a query from the **Character**’s perspective that satisfies the **Requirement** and can be used to retrieve the **Passage**. Please return the result in JSON format.
Here is an example:
<example>
Now, generate the **output** based on the **Character**, **Passage** and language, the **Character** and **Requirement** will be in English. **Requirement** from user, the **Passage** will be in {corpus_language} Ensure to generate only the JSON output, with the key in English and the value in {queries_language} language.
**Character**
{character}
**Passage**
{passage}
**Requirment**
– Type: {type};
– Difficulty: {difficulty};
– Length: the length of the generated sentences should be {length} words;
– Languange: the language in which the results are generated should be {language} language;
模型融合 Slerp:提升模型在不同数据分布下的鲁棒性和泛化能力

性能
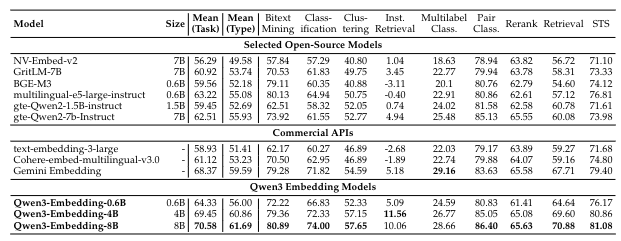
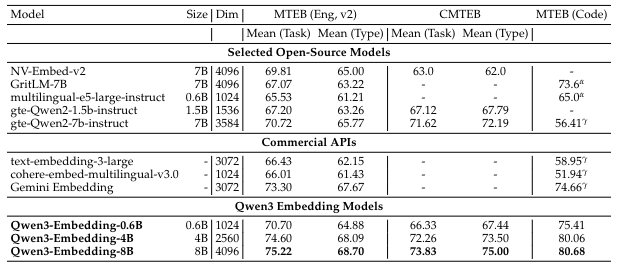
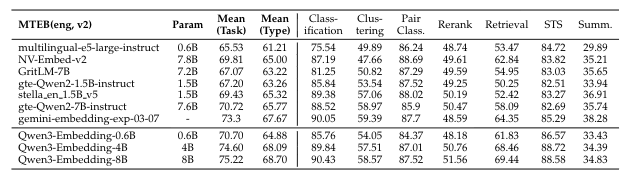
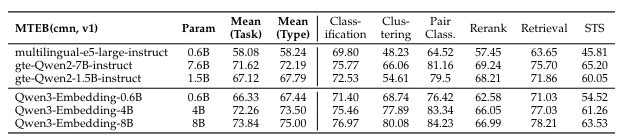
Reranking
输入Query和Document,最后一个token的hidden state,接LM head,输出Yes的Prob
训练方法:SFT+模型融合
性能:
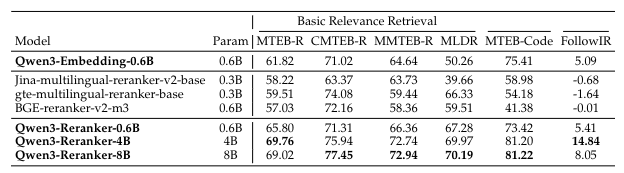
先使用embedding模型检索得到top100,然后重排得到结果
相关文献
Compared Methods We compare our models with the most prominent open-source text embedding models and commercial API services. The open-source models include the GTE (Li et al.,2023; Zhang et al., 2024b), E5 (Wang et al., 2022), and BGE (Xiao et al., 2024) series, as well as NV-Embed-v2 (Lee et al., 2025a), GritLM-7B Muennighoff et al. (2025). The commercial APIs evaluated are text-embedding-3-large from OpenAI, Gemini-embedding from Google, and Cohere-embed-multilingual-v3.0. For reranking, we compare with the rerankers of jina1, mGTE (Zhang et al., 2024b) and BGE-m3 (Chen et al., 2024)
Improving general text embedding model: Tackling task conflict and data imbalance through model merging.
NV-embed: Improved techniques for training LLMs as generalist embedding models.
MTEB: Massive text embedding benchmark.
Rankvicuna: Zero-shot listwise document reranking with open-source large language models.
Gemini embedding: Generalizable embeddings from gemini
![[略读]Big Bird: Transformers for Longer Sequences](https://blog.mclover.cn/wp-content/themes/slanted/img/thumb-medium.png)